Database Considerations
CHAPTER SYNOPSIS
This chapter provides a general discussion of databases, data structure forms, DBMS technology, and their impact on the analytical tasks. A discussion of the roles of the database administrator and the data administrator are also included.
What Is a Database?
A database is a collection of data needed to support and record the business of the firm. These business records include the ongoing records of the firm, the day-to-day business transactions, and any material or information which is used for reference purposes.
Generally speaking a database management system (DBMS) consists of
Using a DBMS:
Databases can reside on:
Databases can contain data that is:
Databases can be:
Databases can be
Centralized versus Decentralized Data Bases
A data base can be characterized as follows:
For each organization segment there is one base of data. The number of data bases within the overall organization is determined by the number of distinct data models that can be developed for the organization.
Both centralized and decentralized data bases can be geographically dispersed or physically contiguous. When an organization maintains more than one data base, and those data bases are not linked in some manner, they are decentralized. When the corporate data base has multiple segments, and they are linked in some manner so that information passes between them or so that portions or copies of the common data can be obtained at each node, then they are centralized but distributed.
Management Levels
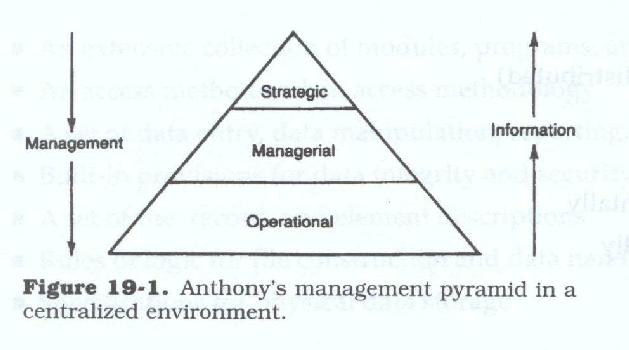
Using Robert Anthony’s pyramid model of management operations occur at the base and strategy at the apex (see Figure 19.1). In the centralized organization, an interchange of data takes place between all units on each level and between levels. A homogeneous data model can be constructed to represent the uses, relationships, and flow of data within the organization. This model can be constructed regardless of the geographic location of the individual functional units.
In a decentralized environment, Anthony's model would appear differently (see Figure 19.2). Multiple discrete data models can be constructed, thus implying different sources, uses, descriptions, and flows of data. It also implies that different entities, relationships, or attributes of entities may exist in each model, or that the entities play a different role in the organizational segment on which the model is based.
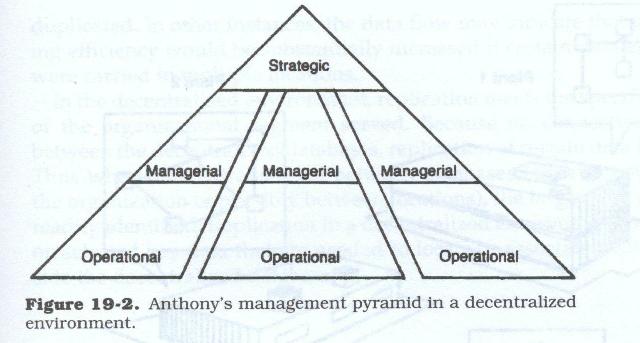
All organizations exhibit aspects of centralized data usage, usually in the strategic or possibly senior managerial levels. Ultimately, all corporate data flows up to the senior levels for review, evaluation, and possibly corrective action or modification. Thus, in the decentralized environment, some portion of a centralized data base is still needed. These centralized data bases in the decentralized environment usually support corporate internal—rather than external—functions (e.g., accounting, budgeting, personnel/payroll).
Another option is a completely decentralized environment consisting of multiple data bases constructed on the same data model and serving the same or very similar functions. A nationwide retail chain system, for example, has geographically separated stores, each supporting a complete but totally separate set of company functions. Although these data bases would have the same structure, because all stores handle the same products and provide the same functions, decentralization might be chosen. This is because each store is a self-contained unit with no need to use data from another store. In this case there is similarity, not commonality, of data usage. If this same chain had different products, different types of customers, and offered different services at each location, then a heterogeneous decentralized environment with dissimilarity of data and thus non-commonality of usage would exist.
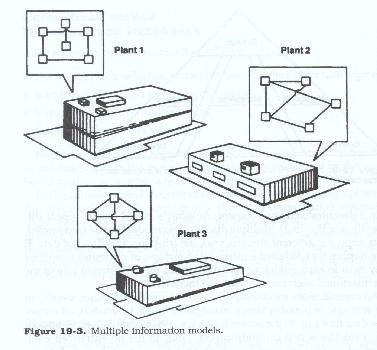
The same concept would hold true if different divisions or operating companies were housed in the same plant or office building and each organization segment provided a completely distinct line of product or service to a completely distinct set of customers. Again, there would be no similarity of data or commonality of usage (see Figure 19.3).
Replication Of Data
In either the centralized or decentralized data base environment, replication of data is not only unavoidable but, in some cases, mandatory. The entities and their attributes and relationships appear in the data base as groups or collections of data elements. Individual data elements may appear in multiple attribute groupings to describe a particular aspect of the entity. Relationships by their nature describe the state or interaction of one entity vis-à-vis another. Since the relationship can be viewed from either entity, some of the elements will necessarily be duplicated. In other instances, the data flow may indicate that processing efficiency would be substantially increased if certain data elements were carried in multiple locations.
In the decentralized environment, replication meets the specific needs of the organizational segment served. Because no connection exists between the decentralized databases, it is valid to replicate certain data. Thus when data is transferred between data bases (usually upward in the organization or possibly between locations), the target entity can be readily identified. Replication in a decentralized environment is mainly on selected key data that is needed to locate or associate entities outside the decentralized data base.
The Centralized Data Base Environment
As is the case with any redesign decision, advantages and risks are associated with each choice. The centralized environment has the obvious advantage of consolidating and integrating data from all parts of the organization into one cohesive unit. This permits both management and operations personnel to obtain required information without regard to its origins, confident that the data thus obtained is accurate, consistent, and time concurrent. It also permits management to view the flow of data through the organization and to access the impact of its decisions. The common definition and single source character of the centralized environment, coupled with standard names and common definitions, allow unambiguous data interpretation.
Data Integration. The logical, structured, controlled storage of data in a common pool allows management access from all parts of the organization and assures that all data reflects the same time value. Data files can thus be transformed from their normal passive role of providing historical support for forthcoming decisions to an active role of controlling (if desired) business operations. The recording of business transactions in files for reporting purposes is transformed into an interactive base, with random retrieval for management and operational decision making.
Management Awareness. Inasmuch as the data base is based on a data model of the organization, the analysis that precedes its definition and construction is useful to all levels of management and operations. The graphic definition of data interaction, flow, and usage provides a clearer framework for understanding how the various functions interact and affect the individual functional unit. The centralized environment by virtue of its shared data usage provides a freer interchange of information and greater cooperation among functional areas. This interchange and cooperation is almost mandatory in a centralized environment and is subject only to the constraints of any security and access restrictions imposed on the installation as a whole.
Privacy and Security. The consolidation and availability of data through a centralized data base requires a more precise definition of the data security profiles of each functional unit. In particular, the organization must define who, when, how, and under what circumstance data may be updated and accessed. The budgeting and forecasting functions illustrate this problem clearly. During the forecasting period, each unit determines its target for the coming periods, based on its estimates of its own activities and those of others such as sales and production. While it is to management's advantage to allow all units access to historical data for projection purposes, it is usually not advantageous to offer forecast data freely in case various units might be influenced by the overly optimistic or pessimistic estimates of others. As a check and balance mechanism, management usually reserves the right to access independent forecasts
Error Proliferation. In the centralized data base environment, the effects of errors are greatly magnified. A single misstatement can cause misinformation to spread throughout the entire organization. This is mitigated if all data is scrutinized by more units than in the non-data base or decentralized environment. This potential for error implies a greater need for editing and cross checking or validation. The converse of this problem, however, is that if data is lost, it is lost to the entire organization and not to just one or two functional units.
Organizational Impact of Change. The centralized data base reflects the data model of the organization, including all of its functions and current lines of business. Should a radical change take place in the business or the entities with which it deals, this impact now affects all areas because of their reliance on the central data pool. A shift in strategy, operational functions, management philosophy, or lines of business can cause a major change in the data model and thus in the central data base. Such a major change can even cause a shift from a centralized to a decentralized environment or vice versa.
Size and Volume. In a data base environment, economies of scale do not always apply. That is, it is more—not less—difficult to handle and control a large data base than a number of small ones. This difficulty is reflected not only in the sheer volume of data, but also in larger user population and the diversity of management levels, style, and functional requirements. The analytical process to develop the model and implement it requires a greater degree of planning and control than a more segmented approach.
The Decentralized Data Base Environment
Whereas organizations utilizing the centralized data base approach are served by a single data base, the decentralized approach consists of multiple data bases each serving some segment. The usual environment for decentralization is one in which multiple independent or semi-independent organizational units are controlled, directed or linked in some manner by a parent unit. This linkage may be as tenuous as sharing common data or uploading or downloading reference data from a common source.
Downloading involves the extraction of data from a central database and normally reformatting it, and or translating it, into a form usable by the receiving system. Uploading involves the reversal of that process. In each case the rules on data modification and data sharing must be carefully documented since there is only an indirect link between the systems.
When referring to a decentralized data base, the distinction is made between it and a data base segment. A decentralized data base is a full and complete unit and the organizational unit or segment that it serves can satisfy all of its data needs from the data base.
Functional Specialization. The thrust toward decentralization is usually aimed at and best suited to functionally specialized organizations. There is no segment of an organization that is completely segregated from all other parts of the organization. At some point, either vertically (the usual manner) or horizontally, there is a data linkage. Therefore, decentralized data bases must provide for these linkages, however tenuous, to external data bases.
Local Differences. Because an organization's information needs reflect management's desires and decision-making processes, no two organizational models are exactly alike. These variations usually result in a customized data base for each unit in a decentralized data base environment. This occurs because opportunities for compromise are limited by diverse data requirements, usage, and definitions at the local level. In effect, each local unit is a separate organization with little in common with other units under the parent company other than that data is fed upwards to senior parent management.
In addition, there is less chance of ambiguity, because generalized data definitions are not required. The units that do share data in a decentralized environment are more homogeneous and can thus more easily derive locally standard definitions and relational structures.
Accounting Differences. Distinct differences in accounting practices can also make decentralization the correct choice. For example, even when producing the same items, an assembly line plant and job shop plant can require vastly different data. Although both plants may manufacture a defense oriented product, one may be marketed domestically and the other overseas. Thus, the reporting and tracking requirements of the plants would differ, possibly to a degree that would make the accounting structures incompatible.
User Proximity. The decentralized data base is closer to the user, has a narrower audience, and tends to serve the individual user better than a centralized data base. Each data administrator within the constraints of the corporate parent's data requirements can organize the decentralized data base for individual needs. Definition and enforcement of corporate data requirements is a must, however, if the parent applications that span multiple divisions and their data bases are to be executed successfully and consolidated correctly.
The finer delineation and definition of data for the specific functional groups within the decentralized environment facilitates local access of data. The creation of overly complex access restriction procedures is usually unnecessary. By definition, non divisional users have no access other than that closely defined and limited by the dictionary processing.
Ownership of data in the decentralized environment is clearly defined. The local data administrator has fewer variables to coordinate when assigning responsibility for and maintaining the quality of the data.
User Confidence. One advantage of decentralized data bases is not inherent in the data itself; rather, it concerns the confidence of the users. The data base becomes their data, and they are more likely to take an active interest in its protection and use. In addition, clarity of data ownership promotes increased data integrity. Any flaw in data base content can be readily traced to the group responsible. This tends to foster greater care in data entry.
Lack of Central Control. Decentralized data bases are the property of the decentralized, not corporate, management. They alone decide what form their data will take. This decision is based in pan on the data entities and relationship with which they deal, and on what data about those entities and relationships decentralized management is interested in. Thus, the coordination of decentralized data bases and their interaction is a difficult task.
Corporate-Level Reporting. The main advantage of the centralized data base environment to upper management is the ability to obtain data related to planning, control, and decision making. Dispersion of data and local definitions in a decentralized environment makes aggregate, cross-unit reports more difficult to prepare.
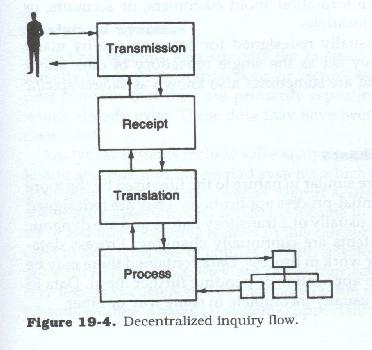
Decentralized data base retrieval from a central location involves a multi-step process of message transmission, receipt, translation, and reduction to eliminate the effects of data dialects (see Figure 19.4). Obviously, more components involved means more operations are necessary to gather all required data.
Time Differential. The relationships that protect against time differentials are strong within the local data base but very weak between local data bases. Each organizational unit operates at its own speed and according to its own time frame.
Although accounting periods usually coincide, the pace at which activity occurs and is recorded differs from unit to unit and site to site. These differences in time reference are transparent to the local users, yet they are detrimental to data that is synthesized centrally from data generated at multiple locations.
Data Redundancy. While redundancy is undesirable in a data base environment, communication between decentralized data bases requires duplication of certain data, thus creating the reference points for correlation. This redundancy reduces the prime advantage of the centralized data base approach: that all users use the same data rather than different, un-synchronized versions.
Each unit maintaining a local data base must either collect the inputs to update the redundant data itself or obtain input data from a central source. The former approach creates discrepancies and inaccuracies; the latter demands increased activity and requires additional management control.
The tendency toward the development or evolution of dialects within the local data definitions also diminishes the effectiveness of common data definition that would be available in the centralized environment.
Loss of Synergy. The synergistic quality of the centralized data base arises from the quantity of data stored and from the global structure used as a framework for the informational model. When this global model is fragmented — as it would be in a decentralized environment — the synergistic quality is lost.
Common Database Types
Reference
Reference databases are, as the name implies, mainly used for reference purposes. They are rather static in nature in that the data contained within them rarely change.
This type of database is usually redesigned to contain information specific to a single major data entity of interest to the firm. For example, a database may contain information about customers, or accounts, or orders, or employees, or locations.
These databases are usually redesigned to be used in common by many diverse applications. They act as the single repository of data about their particular entity. They are sometimes also known as subject-specific databases.
Process related
Process-related databases are similar in nature to the files which are used by the more traditional flat-file sequential-process applications. They are redesigned to contain data which are usually of a transitory nature and are dynamic in use. That is, their contents are continually changing. Process databases are holding bins for work in process. Data contained there may be held between cycles of an application or pending further input. Data in this type of database are usually incomplete in some way or other.
Transactional systems
Transactional systems are those which involve the primary record keeping of the firm. They are the replacement systems for the paper work which drives the business. They may be order processing, customer service, inventory control, statement processing, accounts payable or receivable, or sales support systems. They have in common
These systems are the primary data-gathering and data-generating systems of the firm.
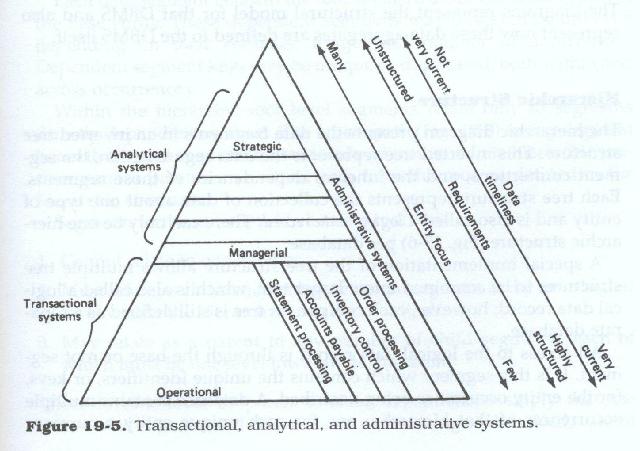
Transactional systems tend to center around processing information about one or two entity types at a time (i.e., customers and accounts, customers and customer orders, vendors and products, etc.), and are normally key-driven. Since they service the operational levels of the firm, transactional systems are vertical in nature. That is, they support the processing and provide for the data needs of a specific user area. The operational area usually has an immediate need for data and to be effective must work with the most current information.
Because of their strong focus on individual entities, their fixed processing requirements, and their limited reliance on multiple entity-to-entity relationships, transactional systems tend to work best within the hierarchic and network models.
Analytical systems
Analytical systems also support the business of the firm but are not directly involved in transactions or record keeping. They are usually post facto, in that they are primarily reporting systems that use data which already exist. These data may have been internally or externally generated.
Analytical systems include sales analysis, most financial reports, marketing analysis, and the myriad of systems which have been called management information systems, decision support systems, etc. Into this category we could also place those functions which have come to be called information center or end-user computing systems.
These types of systems tend to deal with sets of entities or with selected data from many different entity types. Since they are not usually transaction-driven, they tend to rely less on occurrence keys and more on the relationships between the various entities. Analytical systems support the managerial and strategic levels of the firm and are horizontal in nature, i.e., they cut across operational functions. As such their need for data is more extensive, more variable, and usually less immediate than that of the operational level, and their need for data currency is usually much less.
Because of their need for data about multiple entities and their need to relate these entities in multiple ways, analytical systems will work best in the network or relational modes; however, they will perform adequately within the hierarchic model as well.
Administrative systems
The final category comprises the administrative systems of the firm. These systems service the firm as a whole and have little to do with the specific business of the firm. Rather they deal with the firm as an entity.
Administrative systems include human resources, payroll, general ledger, and fixed asset control systems. They are more or less standardized from firm to firm; for the most part, they are self-contained systems. They are only tenuously related to other systems, have their own data sources and files, and only rarely require ongoing data from the operational files of the firm, although they may accept feeds from them.
Administrative systems tend to resemble transactional systems in that they gather data and analytical systems in that they have heavy reporting requirements. They differ in that they tend to focus on one entity type at a time (i.e., employees, accounts, offices, warehouses, etc.) rather than on groups of entity types.
Administrative systems are both vertically and horizontally oriented. They are normally firmwide systems and provide data and support to all areas and levels of the firm. Because of their limited focus on a single or on very few entities and because of the isolated nature of those entities, administrative systems will work best in hierarchic or relational modes.
A Comparison of DBMS Data Structure Options
Database management system products are tools for structuring and managing the application data of the firm. Some firms are in the process of selecting a DBMS for the first time; others are in the process of reevaluating their existing DBMS with an eye toward replacement. Still others have multiple DBMS products in their software portfolio.
The variety of products on the market today offers developers the ability to produce applications using any of three major data structure models: hierarchic, network, or relational. Some products offer more than one of these structural model options.
However, each DBMS has a primary underlying structural model, and thus is more effective with data whose structural characteristics most closely correspond with that specific model. Matching the right DBMS with the structural characteristics of the firm's data can greatly affect the efficiency of the application.
The analyst should develop a data-structure--independent model of the applications data (such as an entity-relationship-attribute data diagram) and translate that model into each of the three structures before evaluating which model is the closest fit.
The analyst should have an understanding of
Aside from the obvious functional differences between applications, most organizations have many different types of systems, each having different scopes and different levels of interaction between the systems. Generally speaking these systems can be categorized into transactional, analytical, and administrative (Figure 19.5).
DBMS Selection Criteria for Mainframe Systems
For mainframe systems the system type influences the type of data needed, the organizational scope of that data, and the way in which it is accessed. Because of these different focuses, the system type becomes a determinant in the DBMS selection.
Each of the data structural models has different operational and implementation characteristics, and these differences influence the capabilities and restrictions of the data structures themselves. Since the natural structure of the data is one of the major factors in the determination of which DBMS is most appropriate, it is important to understand how each structure looks at data and which kinds of data are most suited for each structure.
Each DBMS allows data to be fragmented, according to the same, or very similar, sets of rules and in roughly the same manner; however, each one employs a different method for connecting these fragments into larger logical data structures.
Each DBMS uses a different type of data structure diagram to represent the connection mechanism which it employs. These diagrams depict
The diagrams represent the structural model for that DBMS and also represent how these data aggregates are defined to the DBMS itself.
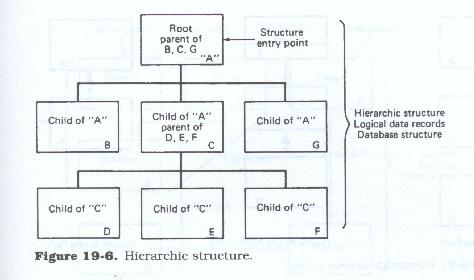
Hierarchic structure
The hierarchic diagram presents the data fragments in an inverted tree structure. This inverted tree represents the data segmentation, the segment connections, and the inherent dependencies of those segments. Each tree structure represents the collection of data about one type of entity and is also called a logical data record. There can only be one hierarchic structure (Figure 19.6 ) per database.
A special implementation of the tree structure allows multiple tree structures to be combined into a larger tree, which is also called a logical data record; however, each component tree is still defined as a separate database.
All access to the logical data record is through the base or root segment. It is this segment which contains the unique identifiers, or keys, for the entity occurrence being described. A database contains multiple occurrences of that hierarchy: one for each unique entity occurrence about which data are stored. Each unique entity occurrence within a given database may have its own configuration of occurrences or non-occurrence of each segment type defined with the general entity hierarchy.
The tree structure diagram normally depicts each segment type only once. However, aside from the root segment of each structure, there can be multiple occurrences of any given dependent segment type within the structure.
Each data segment beneath the root segment describes some aspect of the base entity. These dependent segments may be keyed or un-keyed depending upon their contents, usage, and number of occurrences. Dependent segment keys may be unique or duplicated, both within and across occurrences.
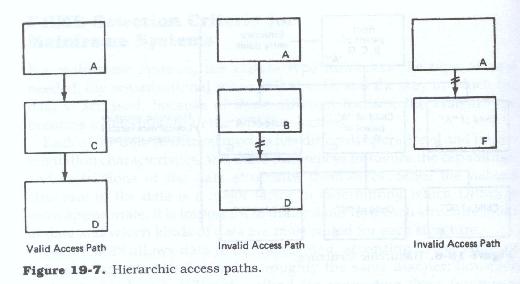
Within the hierarchy, root level segments relate only to segments directly dependent on them. The access path (Figure 19.7) to any segment beneath the root segment must include all its immediate hierarchic predecessors or parents on a direct path from the root, as defined in the hierarchic structure.
Segments at the same level below the root
These level-to-level or parent-to-child dependencies imply that the lower level segments (children) have no meaning and indeed cannot exist without the higher (in terms of position within the hierarchy) level segments (parents).
The hierarchic model is most effective when
Network structure
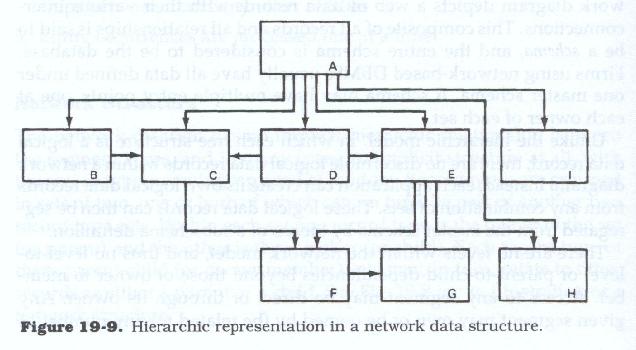
The network diagram has no implicit hierarchic relationship between the segment types, and in many cases no implicit structure at all, with the record types seemingly placed at random. Record types are grouped in sets of two, one or both of which can in turn be part of another two record type set. Within each set one record type is the owner of the set (or parent) and the other is the member (or child). Each record type of these parent-child (or owner-member) sets may in turn relate to other records as either a parent or a child. See Figure 19.8 for an illustration of a network structure.
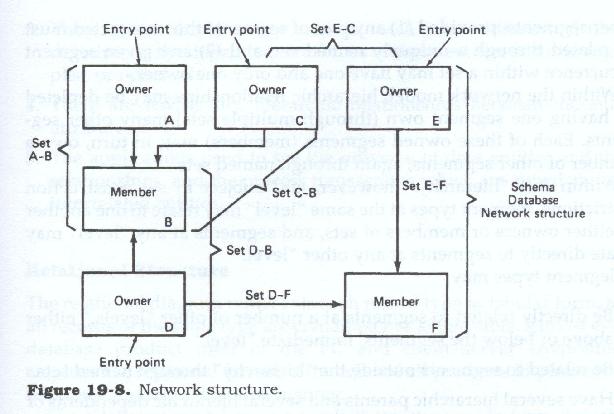
Each record within the overall diagrammatic structure must be either an owner or a member of a set within the structure. Normally, each set is accessed through the owner record type, which contains the identifier, or key, of a specific occurrence of the set type. Each record type may keyed or un-keyed, and key fields may contain unique or duplicated values. Because each record type in each set can be joined to any other record type in any other set, this structure allows highly flexible access paths to be traversed through the various record types for processing purposes.
Since each record can be related to one or more other records, a network diagram depicts a web of data records with their various interconnections. This composite of all records and all relationships is said to be a schema, and the entire schema is considered to be the database. Firms using network-based DBMSs usually have all data defined under one master schema. A schema may have multiple entry points, one at each owner of each set.
Unlike the hierarchic model where each tree structure is a logical data record, there are no discernible logical data records within a network diagram. Instead each application can create its own logical data records from any combination of sets. These logical data records can then be segregated from the master schema by means of a sub-schema definition.
There are no levels within the network model, and thus no level-to-level or parent-to-child dependencies beyond those of owner to member. Access to any segment may be direct or through its owner. Any given segment may own or be owned by (be related to) any number of other segments, provided that
Within the network model, hierarchic relationships may be depicted by having one segment own (through multiple sets) many other segments. Each of these owned segments (members) may in turn own a number of other segment, again through named sets.
Within this "hierarchy," however, and subject to set construction restrictions, segment types at the same "level" may relate to each other as either owners or members of sets, and segments at any "level" may relate directly to segments at any other "level."
Segment types may
The network model is most effective when
Relational structure
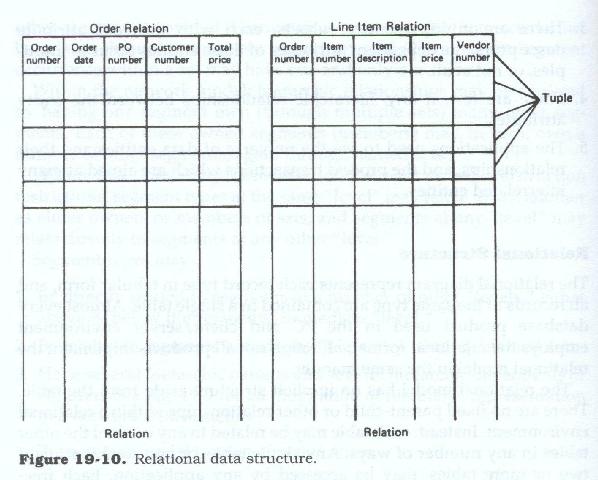
The relational diagram represents each record type in tabular form, and all records of the same type are contained in a single table. Almost every database product used in the personal computer and client server environment employs the relational format, although not all products implement the relational model in the same manner.
The relational model has no implicit structure aside from the table. There are no fixed parent-child nor other relationships within a relational environment. Instead, each table may be related to any or all of the other tables in any number of ways. Any single table, or any combination of two or more tables, may be accessed by any application. Each freestanding table is known as a relation, and each entry within each table is known as a tuple or, more commonly, as a row. Figure 19.10 shows a relational data structure.
Whereas within the network and hierarchic models all data manipulation operations are "record at a time" (where each record must be accessed through its key or through its relationship with, or proximity to, another record), data manipulation within the relational model is "set (or table) at a time" where the set of rows accessed may be as few as one or as many as exist in the table.
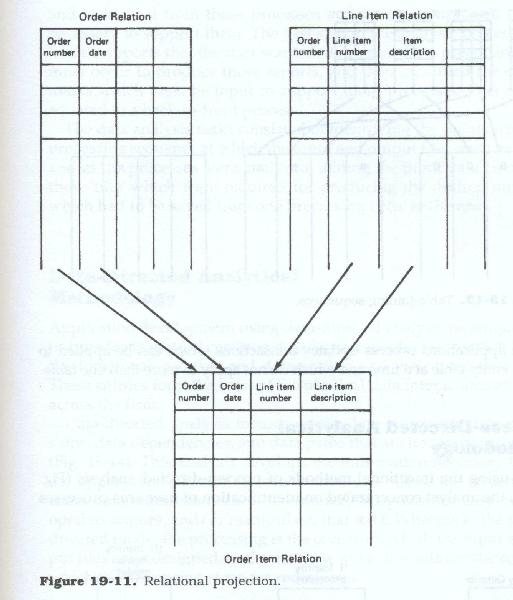
Each application can create its own logical data records from any combination of tables, or portions of tables, as needed. These logical data records can then be accessed and manipulated by means of user views or "projections" (Figure 19.11).
Although each data table contains data assigned according to a primary key for the entries of the table, there is no explicit sequence to the entries of a table, and the table may be accessed via the contents of any field (or column) of data with it. A table may contain any number of rows, and within a table a row may contain any number of data elements, with the restriction that all data elements must be atomic; that is, they must be defined at their lowest possible level, they must be non-repeating, and within a table they must be uniquely named.
Each table must have a column of data elements defined as a primary key, and the primary key field of each row must contain a unique value. All occurrences of a data element within a given column of a table must be identically defined and must contain a data value or a null entry.
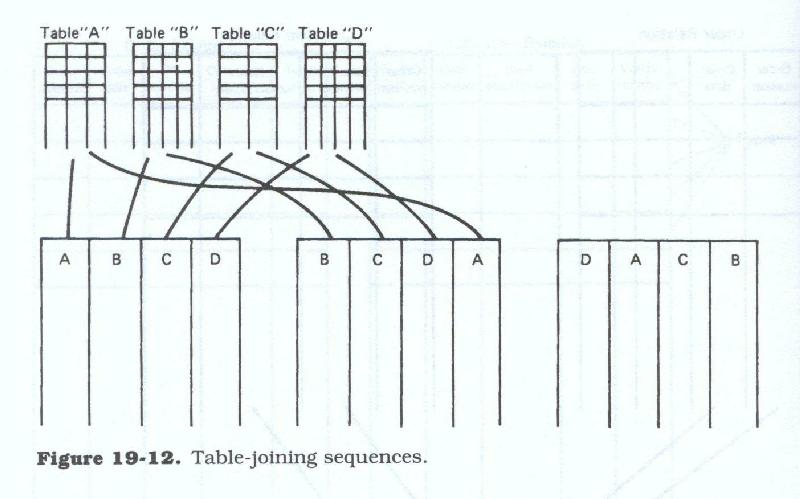
Tables may be related, or joined, in any sequence (Figure 19.12); any table may start the sequence of joins; and a table may be joined to itself. Any number of tables may be related together, provided that each table of each pair of tables to be joined has a column of data which is identical in definition and is populated from an identical range of values (or domain). Any given table may be directly joined with only two other tables at any one time (A to B and B to C) and the tables must be connected in sequence (A to B, B to C, C to D, etc.), although the sequence of table joins (ABCD, CDBA, DCBA, etc.) is immaterial.
The relational model is most effective when
Process-directed Analytical Methodology
When using the traditional methods of process-directed analysis (Figure 19.13), the analyst concentrated on identification of user area processes and tasks, and from those processes and tasks, extrapolated the data necessary to support them. The first step in the analysis process identified the reports that the user wanted, determined the processing which must occur to produce those reports, and then identified the data elements which must be input to support those processes. This could be equated to a back-to-front process.
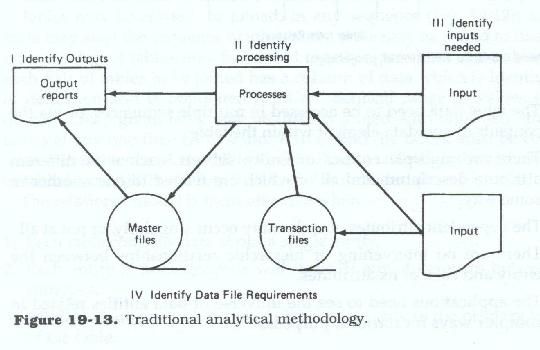
The data analysis tasks consisted of identifying the points within the processing sequence at which the input and output files must be placed, and as the processes were analyzed, adding the input data elements to those files which were required for producing the desired output, or which had to be saved from one processing cycle to the next.
Data-directed Analytical Methodology
Application development using data-directed analysis techniques, with its broader scope and common data focus, includes tasks which identify the functional, process, and data entities and their relationships to each other. These entities form the basis of the physical data interactions and usage across the firm.
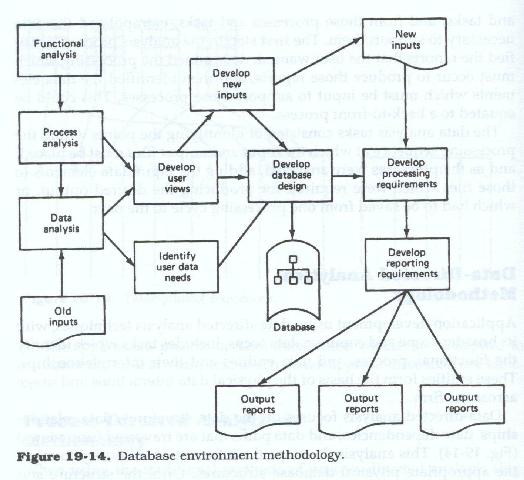
Data-directed analysis focuses on the data structures, data relationships, data dependencies, and data paths that are traversed (user views) (Figure 19.14). This analysis develops the information necessary to select the appropriate physical database structures. Once the determination of the structure and users data requirements are completed, the processes may be developed to acquire, and/or manipulate, that data. Whereas in the process-directed mode, the processing is the core from which the input and output files are redesigned, in the database mode the data are the core from which the processing steps are redesigned.
User Views
We have discussed the need for developing user views of the data. At this point we should provide a definition of a user view.
A definition
A user view (of data) consists of the data elements needed for the user to perform a specific function, such as process a transaction. The user view incorporates the data elements which are received, the reference data elements needed to process that input, and the data elements which are finally stored in the files of the firm.
At each point in the sequence of a specific process, we need to know the primary identifiers or keys of the input data, the identifiers or data elements which will be used to search the reference files, and the identifiers under which the data will be finally stored. If the data are input in a fragmented form, or if the reference data are retrieved in a fragmented form, or if the data are stored in a fragmented form, the analyst needs to identify the sequence and content of each fragment. Normally, the input, retrieved, or stored data will be more or less coherent. That is it will all be related to a common order, employee, vendor, etc.
User views are usually developed on a transaction-by-transaction basis, although they can also be developed for query and report processing. They detail what data are needed, in what sequence they are needed, and what data identifiers (keys) are relevant. They also identify what processing is performed on the data, in terms of editing, validation, verification, processing, and storage.
User views are needed to identify the basic data element requirements of the users. They are also needed to determine what data are needed in conjunction with other data and to identify when those data are needed. Each user view should be supported by a transaction, a query screen, a report, or a combination of all three.
User views are developed as a result of process and task analysis, transaction and report analysis, and source and usage analysis. Each user view should be supportable by the data file redesign and by the processing sequences which have been developed. Each user view should be capable of being walked through the data file redesign, and all data and identifiers should be present in the user view "path" when needed.
Data-Directed Analysis and the Entity-Relationship Approach
Analyzing integrated applications differs in distinct ways from analyzing processes of more traditional single-user applications. The major differences are in the identification of the central redesign framework; integration of data and its processing, orientation, and sequence of steps; and the inclusion of business entity, business entity relationships, and business entity data analysis.
The analysis and redesign of integrated applications relies heavily on models as one of its integration mechanisms. One of the primary modeling techniques is that of the entity-relationship approach; the others include data flow diagrams and hierarchic process diagrams as well. For instance, the entity-relationship approach refocuses the analyst on the interaction of the functional, processing, and data entities of the firm, their relationships to each other, and their physical characteristics or attributes.
Using this approach, the analyst can build the redesign around the identification, analysis, description, and interaction (relationships) of these real-world functions, processes, and data entities of the business.
Effective use of the entity-relationship approach, however, requires clear definitions of the terminology and a clear understanding of the concepts involved. The requirement for a clear understanding of the environment is as applicable in the analytical phases as it is in the development of the entity-relationship models; the hesitancy on the part of analysts to develop "models" has hindered the more widespread use of the entity-relationship approach as an analytical tool.
Since the data entities are real, in that they physically exist, they are readily observable. Being real, they interact or relate to each other to accomplish the business of the firm, and they are also relatively stable, and more important, visible and readily describable. They are, in fact, some of the most stable objects in the business environment, more so than business functions or even business processes.
This business entity data analysis looks at the sources of the firm's data and follows the flow of that data through the various business functions and processing steps. Within each function and processing step, the uses and modifications to that original data are examined and documented.
This source and usage analysis results in the identification of the major data entities of the firm, the attributes of those entities which are of interest to the firm, and the natural business relationships which exist between those entities.
The data are arranged into records, and the records are arranged into a logical database structure. The structural logic of the data is then transformed into the physical implementation of the database (physical schema). These analytical steps and transformations are accomplished in an orderly and formalized manner, using new tools and techniques aimed at achieving proper data placement, data access paths to be traversed, and access key requirements.
This analysis, called data analysis, is achieved mainly through the development and use of modeling techniques. These models allow both the developer and the end-user to define a data model of the business or business segment for which the system is being developed.
This data model of the business, its business functions and transactions, or data events, may be used to ensure that the data have been both properly identified and structured and that the appropriate processing of that data is occurring, or will occur.
The development of the methodological documentation deliverables and of the analytical models may occur concurrently; the documentation may precede the modeling effort, or more appropriately the development of the documentation deliverables and the models may be interwoven.
While the relationships are not exact, the phases of the integrated application redesign process include all traditional application system development methodology phases plus additional phases which have been structured to place the narrative documentation in perspective through the use of a series of models.
In practice, the information developed in the documentation portions of the methodology provides the bulk of the data, background, and analysis for the additional phases in the expanded methodology.
Data Administration
The data administration (DA) function, along with database administration, is one of the most vaguely defined functions. In many organizations data administration is the name applied to the overall database control and support organization (DSCO). Literally its function is the administration, or management, of data. It is usually more involved with the applications development process and business analysis than with the software aspects of a database environment.
The data administrator normally has the responsibility for the development of corporate standards for data naming and for data definition. The responsibility for data definition extends not only to the information systems implementations of data (i.e., programming language names, internal storage representations, etc.) but also to the business implementations as well. That is to say, he or she has the responsibility of ensuring that the business definitions of the data are clear, accurate, and acceptable to the user community as a whole.
For instance, while the definition of employee date of birth might be fairly straightforward, the definition of date of hire, date of employment, or date of promotion might not be as clear or easy. It is the responsibility of the data administration staff to edit, research, and in some cases rewrite the definitions until they are clear to all and have the same meaning to all.
The focus of the data administrator is more on redesign and analysis than on implementation. As one of the controlling functions of the database control and support organization, data administration provides architectural guidance and support. Its medium is the data, its structure, and usage. The tools are the dictionary and its supporting software.
As such it falls on the managerial end of the responsibility continuum, the end-user end of scope continuum, and the analytical end of the role continuum (Figure 19.15). Data administration's focus is on the early to middle stages of the development life cycle.

Database Administration
If the data administrator is the architect of the database control and support organization, then using the same analogy, the database administrator (DBA) is the general contractor. His or her focus is on software and its implementation, performance, and tuning. With data administration, it is one of the controlling functions and provides technical support and architecture.
Its medium is the DBMS and its access and support software. The tools are the DBMS software and its supporting utilities. The database administrator and staff are among the most technically proficient personnel in the organization, with primary responsibility for the integrity, security, and performance of the physical files of the database. Its function is one of the most critical in the DCSO.
Its profile places it on the technical end of the role continuum, on the managerial end of the responsibility continuum, and on the development end of the scope continuum (Figure 19.16). Database administration focuses on the middle through the final stages of the development life cycle. In addition, it is active through the post-implementation life of the application.
A Professional's Guide to Systems Analysis, Second Edition
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.