Translating the Data Model for Implementation
Each of the data structural models has different operational and implementation characteristics, and these differences influence the capabilities and restrictions of the data structures themselves. The natural structure of the data is one of the major factors in the determination of which DBMS is most appropriate: thus, it is important to understand how each structure looks at data and which kinds of data are most suited for each structure.
Each DBMS allows data to be fragmented, according to the same or very similar sets of rules, and in roughly the same manner. They differ in the manner each employs for connecting those fragments into larger logical data structures.
Each DBMS uses a different type of data structure diagram that depicts:
The data model view of the hierarchic model
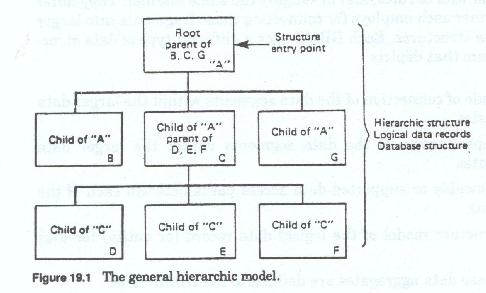
The hierarchic diagram (Figure 19-1) presents the data fragments in a an inverted tree structure. This inverted tree represents the data segmentation, the segment connections, and the inherent dependencies of those segments. Each tree structure represents the collection of data about one type of entity and is also called a logical data record. There can only be one hierarchic structure per data base. A special implementation of the tree structure allows multiple tree structures to be combined into a larger tree, which is also called a logical data record: however each component tree is still defined as a separate data base.
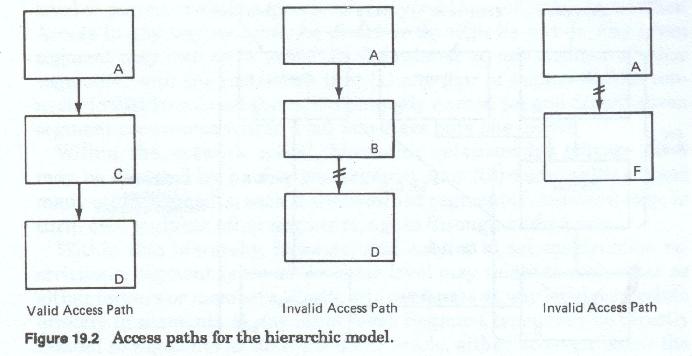
All access to the logical data record is through the base (Figure 19-2) or root segment. It is this segment that contains the unique identifier(s), or Keys, for the entity occurrence being described. A data base contains multiple tree occurrences, each of which pertains to aspecific entity occurrence. Each unique entity within a given data base may have its own configuration of occurrences or non-occurrences of each segment type defined for the general entity hierarchy.
The tree structure diagram depicts each segment type only once. However, aside from the roots segment of each structure, there can be multiple occurrences of any given dependent segment type within the structure. Each data segment beneath the root segment describes some aspect of the base entity. These dependent segments may be keyed, or unkeyed, depending on their contents, usage, and number of occurrences. Dependent segments segment keys may be unique, or duplicated, both within and across occurrences.
Within the hierarchy, root level segments relate only to segments directly dependent to them. The access path to any segment beneath the root segment must include all of its immediate hierarchic predecessors, or parents, on a direct path from the root, as defined in the hierarchic structure.
Segments at the same level below the root:
These level-to-level, or parent-to-child, dependencies, imply that the lower level segments (children) have no meaning and indeed, cannot exist without the higher (in terms of position within the hierarchy) level segments (parents).
The hierarchic model is most effective when:
The data model view of the network model
The network diagram (Figure 19-3) has no implicit hierarchic relationship between the segment types and in many cases, no implicit structure at all, with the record types seemingly placed at random. Record types are grouped in sets of two, one or both of which can, in turn, be part of another two-record type set. Within each set, one record type is the owner of this set (or parent) and the other is the member (or child). Each record type of these parent-child (or owner-member) sets may, in turn relate to other records as a parent or a child. Each set represents data about a specific entity, and thus each owner is keyed uniquely.
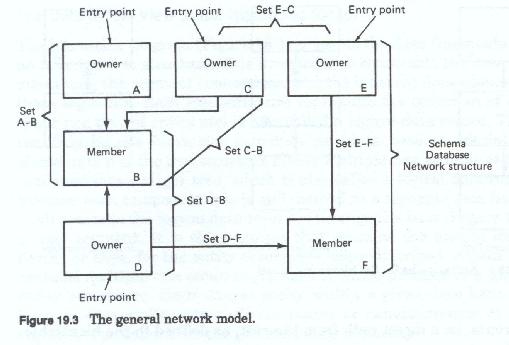
Each record within the overall diagrammatic structure must be either an owner or a member of a set within the structure. Normally, each set is accessed through the owner record type, each of which contains the identifier, or key, of a specific occurrence of the set type. Each record type may be keyed or unkeyed, and key fields may contain unique or duplicated values. Because each record type in each set can be joined to any other record type in any other set, this structure allows highly flexible access paths through the various record types for processing purposes.
Because each record can be related to one or more other records, a network diagram depicts a web of data records with their various interconnections. This composite of all records and all relationships is said to be a schema, and the entire schema is considered to be the data base. Firms using network-based DBMSs usually have all data defined under one master schema. A schema may have multiple entry points, one at each owner of each set.
Unlike the hierarchic model, where each tree structure is a logical data record, there are no discernible logical data records within a network diagram. Instead each application can create its own logical data records from any combination of sets. These logical data records can then be segregated from the master schema by means of a subschema definition.
There are no levels within the network model and thus, no level-to-level or parent-to-child dependencies beyond those of owner to member Access to any segment may be direct or through its owner. Any given segment may own or be owned by (be related ) any number of other segments, with the restriction that
Within the network model, hierarchic relationships (Figure 19-4) may be depicted by having one segment own (through multiple sets) many other segments; each of these owned segments (members) may, in turn, own multiple other segments, again through named sets.
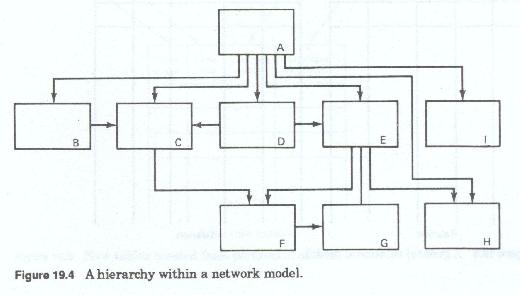
Within this hierarchy, however and subject to set construction restrictions, segment types at the same level may relate to each other as either owners or members of sets, and segments at any level may relate directly to segments at any other level. Segment types may be directly related to segments at multiple other levels, either above or below the immediate level of the segments, may be related to segments outside the hierarchy through named sets, and may have multiple hierarchic parents and multiple hierarchic dependents or children.
The network model is most effective when:
The data model view of the relational model
The relational diagram (Figure 19-5) represents each record type in tabular form, and all records of the same type are contained in a single table. Thus the relational model is organized around record types and not around entities.
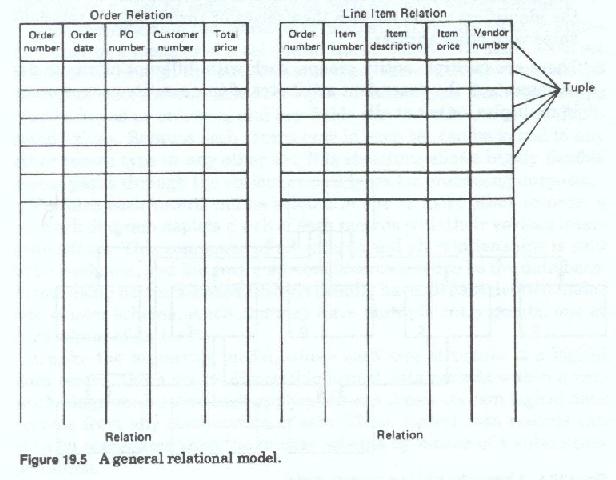
The relational model has no implicit structure aside from the table. There are no fixed parent-child or any other relationships within a relational environment. Instead, each table may be related to any or all of the other tables in any number of ways. Any single table, or any combination of two or more tables, may be accessed by any application. Unlike the network and hierarchic models the relational model does not support any physical record to record connections.
Each freestanding table is known as a relation, and each entry within each table is known as a tuple, or more commonly, a row. Whereas all data manipulation operations are "record at a time" (where each record must be accessed through its key or through its relationship with, or proximity to, another record) within the network and hierarchic models, data manipulation within the relational model is "set (or table) at a time," where the set of rows accessed may be as few one or as many as exist in the table.
Each application can create its own logical data records (Figure 19-6) from any combinations, or portions of tables as needed. These logical data records can then be accessed and manipulated by means of user views or "projections."

Although each data table contains data assigned according to a primary key for the entries of the table, there is no explicit sequence to the entries of a table, and the table may be accessed via the contents of any field (or column) of data within it.
A table may contain any number of rows, and a row within a table may contain any number of data elements, with the restriction that all data elements must be atomic, i.e. they must be defined at their lowest possible level of decomposition, they must be nonrepeating, and they must be uniquely named within a table. Each table must have a data element column(s) defined as a primary key, to permit each row tobe uniquely identified, and the primary key field of each row must contain a unique value: all occurrences of a data element within a given column of a table must be identically defined and must contain a data value or a null entry. Each row of a given table must have an identical set of data elements.
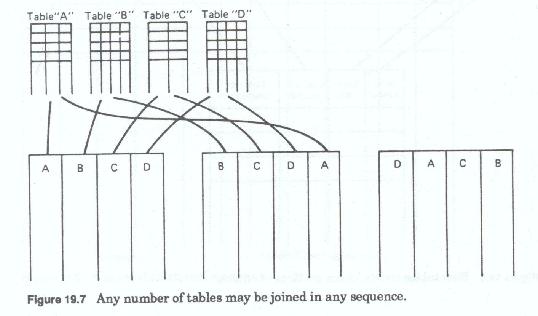
Tables may be related, or joined in any sequence, any table may start the sequence of joins, and a table may be joined to itself. Any number of tables (Figure 19-7) may be related together, provided that each table, or each pair of tables. to be joined has a column of data that is identical in definition and is populated from an identical range of values (or domain). Any given table can be directly joined with only two other tables at any one time and the tables must be connected in sequence, although the sequence of table joins is immaterial.
The relational model is most effective when:
Translating attributes into Records
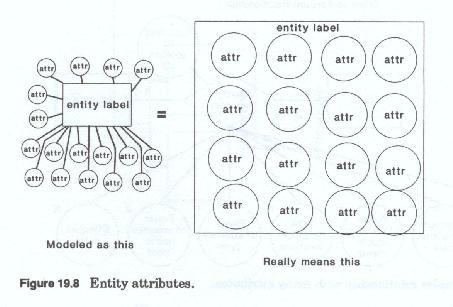
The entity based data model calls for the representation of each distinct attribute for each entity (Figure 19-8) and each relationship. An attribute may be a descriptor or an identifier or it may be some physical characteristic - a record of some action taken or a status descriptor. Generally, an attribute refers to a distinct category of data or information of interest about the entity, or some category of data that describes or qualifies a relationship. An attribute should not be equated to a data element, although in some cases a single data element may suffice to describe the attribute. Generally, an attribute will require more than one data element for full definition.
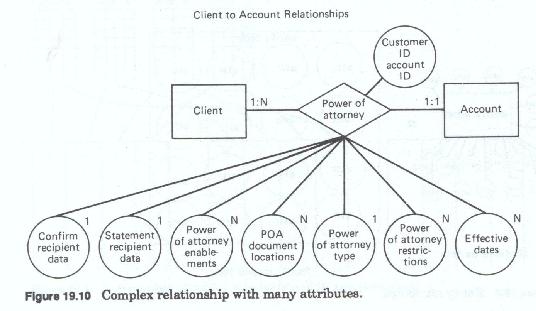
Relationships usually have very few (Figure 19-9) attributes, although a complex relationship may have as many as a dozen or more. Entities, on the other hand, may have several dozen (Figure 19-10) attributes. The number of attributes depends on the level of interest that the firm has in the entity, the number of things the firm must know about the entity and , more importantly, how the attributes were named and defined (the number of data elements needed to store the desired information (Figure 19-11) about the attribute).

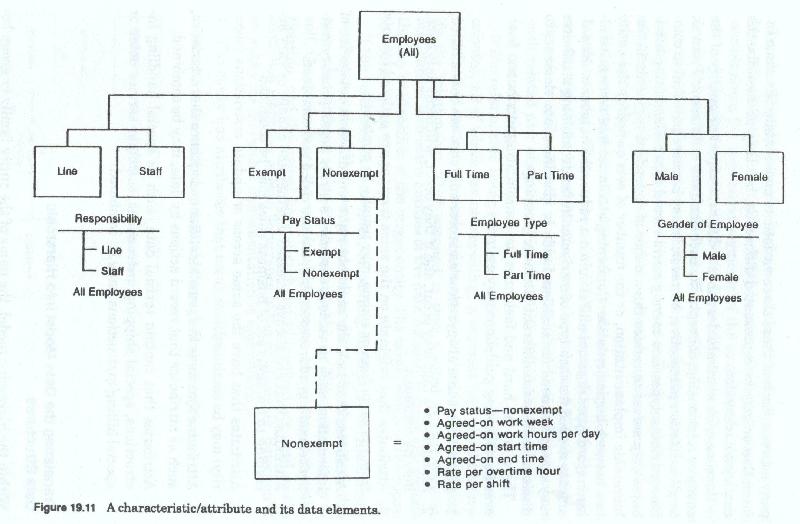
For instance, an employee entity may have a single attribute called education, it may have two different education attributes - one internal and one external - or it may have a complex set of education attributes such as high school, college, graduate school, vendor courses, and company courses. Each of these three variations may contain the same information or may be represented differently, but they all describe the employee's education.
Because each attribute describes a different aspect or quality of the entity or relationship, conceptually each attribute is different. From an implementation perspective, however, it may be more practical to combine attribute types into more general record types.
Combining attributes only serves to reduce the number of dependent segments in the hierarchic implementation, or the number of sets owned by the entity in a network implementation. Combining attributes into more generalized record types does not and should not reduce thenumber of data elements needed for each type of attribute. In fact, combining attributes may create the need for additional code or identifier data elements to distinguish between different attribute groupings.
There are no hard and fast rules for consolidating attributes; however the following guidelines may assist:
Translating the data model into hierarchic data structures
Within the hierarchic model, the name of the entity family or group, becomes the name of the hierarchic structure. All name or identifier attributes for the entity family or group would be collected and aggregated into the root segment of the hierarchic structure. Any uniquely occurring identifier attribute can be chose as the structure access key (root key). All other attributes of the entity become, either individually or in combination the dependent segments of the root. Because of their direct relationship to the entity, entity hierarchies normally contain two levels, the root and the dependent. If any of the dependent segments represent data about characteristics which are further qualified by dependent characteristics then a third or even a fourth level of segment may be used. Third and fourth level segments may also be used for history segments.
Relationships within the hierarchic model can be implemented in a number of ways. They can be either DBMS, or programmatically maintained and can reside within the hierarchic structure of each entity of the pair or independently of either entity. The relationships between each related pair of entities (Figure 19-12 and 19-13) must be examined one at a time.
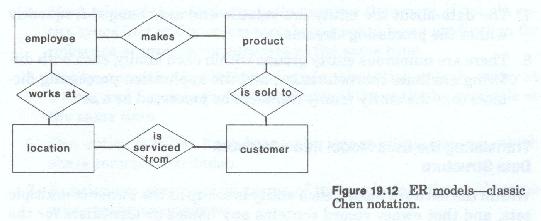
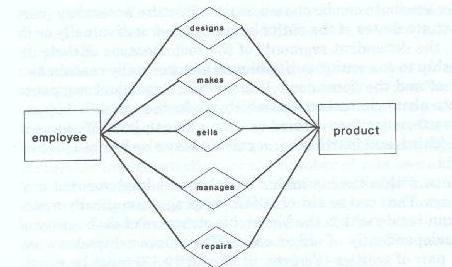
If the relationship being examined is simple, i.e. if it has few attributes, all of which are nonrepeating, a segment type should be created for it to contain the nonkey data elements that describe and qualify the relationship. That segment is then treated as if it were an attribute of each of the entities of the pair. As such, it must also contain the key or identifier of the target entity. the target entity is the opposing entity of the related pair.
If the relationship is complex, containing multiple or multioccurring attributes, it should be maintained independently of each entity. In this case, a hierarchy is set up for the relationship as if it were an entity itself, the attributes of the relationship become dependents of the relationship, and the paired keys of each entity involved are used as the combined identifier of each occurrence of the relationship. Selection of an entity for hierarchic implementation is appropriate if:
Translating the data model into a network data structure
Within the network model, each entity is set up as the owner of multiple sets, and that owner record contains any names or identifiers for the entity occurrence. Each attribute or combination of attributes becomes a member record of a set with the entity record as its owner.
Relationships within the network model can be implemented in a number of ways. They can be either DBMS or programmatically maintained and can reside as a set within the structure of each entity of the pair or independently of either entity. As with the hierarchic translation,the relationships between each related pair of entities must be examined one at a time.
If the relationship is simple, i.e. if it has few attributes, all of which are nonrepeating, a record type should be created for it to contain the nonkey attributes that describe and qualify the relationship. These records become intersection records, which are owned by each of the related entity occurrences.
If the relationship is complex and contains multiple or multioccurring attributes, it should be maintained independently of each entity. In this case, a hierarchy or cluster is set up for the relationship if it were an entity itself, the attributes of the relationship become members of sets of the relationship entity, and the paired keys of each entity involved are used as the combined identifier of each occurrence of the relationship entity owner. That owner record is then treated as if it were an intersection record between each of the entities of the pair.
Selection of a network implementation is appropriate if:
Translating the data model into relational data structures
Within the relational model, only entities with certain characteristics, and without others can translate into relational tables. The attributes of the entity, the number of occurrences of each attribute, the complexity of the relationships between those entities, and the number of groups into which each entity family has been decomposed all become determining factors.
Each distinct entity family or group becomes a relational table. The columns of the table include the identifiers of the entity and the data elements of its nonrepeating attributes. In cases where some of the entity attributes occur multiple times, each distinct attribute type that does so must be established as a separate table and keyed with the identifiers of the entity family in addition to any other characteristics or data elements required to distinguish between repetition occurrences
As with the network and hierarchic models, simple and complex relationships must be handled differently. If the relationship is simple, i.e. if it has few attributes, all of which are nonrepeating, a single table can be created for it. Each row of that table implements a specific relationship occurrence between the two entities. The table should contain a pair of columns, where each column contains one of the paired keys of the related entities. These paired keys act as the identifier of each relationship occurrence. The remainder of the columns in the table contain the data elements of the attributes that describe and qualify the relationship. Eachseparate relationship type between each entity pair should be converted to a separate table.
Complex relationships, or those containing multiple or multioccurring attributes, should be treated as if they were entities with repeating attributes. The base table of this relationship entity should contain the data elements of all nonrepeating attributes, and a separate table must be set up for each repeating attribute type of the relationship. Each table of the relationship set must contain a set of columns, each of which contains one of the paired keys of the related entities.
Selection of an entity for relational implementation is appropriate if:
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell.
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.