
Entity Families, Attributes and Normalization
Regardless of how well the definitions are written or the entity groups and entity families constructed, not all members of a group will be exactly alike. A model where all group members are exactly alike would be excessively cumbersome and would in all probability result in an overly large number of very small groups. Thus the data model seeks composite descriptions. Descriptions which cover all possible member attribute configurations.
However, each entity occurrence is also unique in that it has its own distinct set of physical attributes (descriptors), operational attributes and relationships. Thus the assumption cannot be made that all data elements within the composite model of the entity family will, or even should, be present or active for any given entity group or entity occurrence of the entity family. On a composite basis however, all of the attributes and data elements are needed to describe the entities in the family.
Just as there are various groups of entities within a family, there are also various groups of attributes with the data model which correspond to those groups. For instance, all customers have demographic attributes, however the demographic data for a doctor and a teacher are different and these in turn are different from the demographics of a school which in turn is different from those of a hospital. If doctors, teachers, schools and hospitals are all customers then the demographic attributes for each kind of customer are determined by a characteristic of that customer - type of customer (doctor, teacher, school, hospital).
The attributes of entity occurrences, entity groups and entity families are determined partly by the characteristics of each, and partly by the data indicated by the business rules of the firm states. Different types of attribute data are dependent upon the characteristic value. In the same manner that characteristics are cumulative (they chain together in increasingly longer chains), attributes also chain together in increasingly longer chains.
Attributes, Characteristics and Data Elements
For purposes of explanation and further discussion we will repeat our earlier definitions of attribute and characteristic and add a definition for data element.
An attribute is some aspect or descriptor of an entity. The entity is described in terms of its attributes. An attribute may contain one or more highly interrelated data elements. Attributes have no meaning, existence or interest to the firm except in terms of the entity they describe.
A characteristic is a special multipurpose, single data element attribute whose discrete values serve to identify, describe, or otherwise distinguish or set apart one thing or group of things from another.
A data element is the smallest, meaningful unit of data within the data model.
A data group is a collection of data elements which have been given a group name for purposes of documentation reference or processing convenience. A data group may be as small as two data elements or it may be a reference to a very large (defined or undefined) group of data elements. Some examples of a data groups are:
An attribute is a data group containing very specific, interrelated data, and is treated in much the same manner as we treat entity groups. Figure 18-1 illustrates the relationship between attributes, data groups and data elements. We breakdown or decompose attributes in the same manner as we breakdown the entity family. In fact since the entity family is a data model construct we can say that the entity family represents the label of all data needed about the entities in that family. The entity group represents only the data which is specific to that entity group. Thus, as we group entities within the family we are also grouping data at the same time, since each entity group also identifies some specific type of data which makes it different from other entity groups. The minimum data difference between entity groups is the characteristic value which determined the group membership.
An attribute may be a very abstract or general category of information (at the entity family level), a specific element of data (at the entity occurrence level), or a level of aggregation between these two extremes (at the entity group level). Most attributes appear as clusters of highly interrelated elements of data which in combination describe the specific aspect of the entity as represented and identified by its characteristics. Each characteristic identifies a different group of data elements. Even attributes or data groups which appear not to be characteristic based are - for the most part they are based upon the entity occurrence identifier characteristic. The data values of attribute data elements are not critical to the development of the data model and in most cases they are unique to an entity occurrence. Only characteristic values are critical. The data model must however document the valid ranges of the data element content, their format, editing rules, etc.
The following will illustrate the relationship between attributes, characteristics and data elements.
In a previous illustration (figure 18-2) we had two named groups - exempt employees and nonexempt employees pay status (nonexempt, exempt).
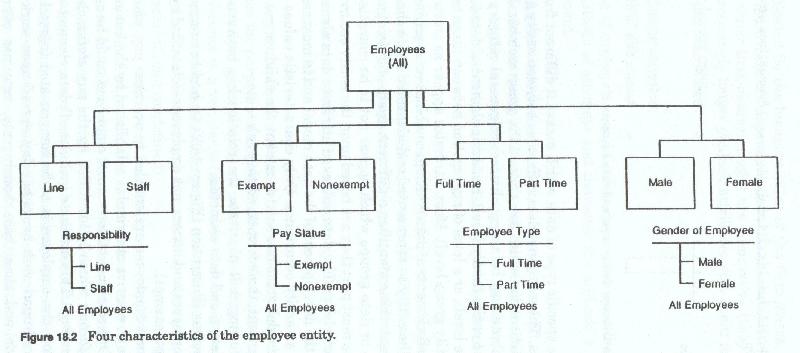
Nonexempt employees are entitled to overtime pay, which is calculated through a series of formulas established by the business rules of the firm. One attribute of nonexempt employees could be called nonexempt pay factors which is identified by the pay status characteristic value nonexempt.
This attribute includes all data elements used to determine how the employee is to be compensated (agreed upon work week, agreed upon work hours per day, agreed upon work start time, agreed upon end time, base hourly rate, rate per overtime hour, rates/shift, etc.) all of which are needed to determine when what the base pay is, when overtime is to be paid and how much is to be paid for overtime.
This characteristic dependent group of data (attribute) could be expressed as a formula (with illustrative values) as follows:
If the business rules determined that overtime was based upon the shift worked instead of a rate for each hour over the agreed upon hours, then an additional characteristic would be needed - shift worked (first shift, second, shift. third shift, fourth shift) and there would be one attribute for nonexempt (data common to all nonexempt employees, and one attribute for each shift.
These characteristic dependent groups of data (attributes) could be expressed as a series of formulas (with illustrative values) as follows:
There would also be attributes for third and fourth shift pay factors. Each attribute illustrated above is identified by a specific set of values of a specific set of characteristics. The combination of independent and dependent characteristic values (pay status and shift worked respectively) is the chain which identifies that attribute. All of the elements in each attribute work as a group, and each attribute is relevant to a specific fact of the employee. It should be obvious that (repeating) characteristic dependent data groups in reality could, and do, represent smaller groups of employees (a further qualification of pay status by the characteristic shift worked).
Classification and normalization
Normalization is an after-the-fact process for correcting the grouping of data when a design is developed inductively. Classification is a before-the-fact process for grouping data when a design is developed deductively.
Put another way normalization is classification performed in bottom-up design, classification is normalization performed in top-down design.
Both processes attempt to determine the proper groupings of data for maximum data integrity. The term data integrity is used to describe that property of data which refers to its resilience to inadvertent and unintentional change. Inadvertent change may occur when a change is made to one type of data and that change also changes the meaning, but not necessarily the values of other data associated with it. For instance, assume that an address is associated with a customer record. If we also assume that the customer's telephone number is stored in another part of the file. It is possible to change either the address or the phone number which are dependent upon each other, without changing both. This causes a data inconsistency. If each address has a city name, state and zip code associated with it, it is possible for the zip code in one record to reflect a different city and or state than in another, when in fact a zip code uniquely identifies both city and state. Again a data inconsistency within the file.
Another kind of data integrity problem manifests itself when one part of related data is removed from the file while another remains. For instance,if we assume that vendor invoices are stored in one part of the file and vendor information is stored in another, than it is possible for the vendor information to be removed while the vendor invoice still remains.
Another more subtle form of data integrity problem may arise when seemingly independent data is stored independently and is subsequently found to be dependent. For instance, assume an order is written for a particular part,and the customer is quoted a price from the part description file. If that is the only place the price is stored, than if that price subsequently changes, it may retroactively change all orders which use that file for reference. In this case the quoted price for the part should have been stored with the invoice line item since it is dependent on the order and date, or the prior prices for the part should have been saved with their effective dates (from and to) so that the original quoted price for the invoice could be retained.
The topic of normalization was first proposed by E.F. Codd within the context of his description of the relational database form. Normalization has been expanded upon and commented upon by both C.J. Date and William Kent. Today, there are many variations of the normal forms, but the most popular is known as the Codd-Date-Kent normal forms. These normal forms are expressed as a set of rules, which if followed will arrange data for storage in a manner such that its integrity is virtually assured. There are three basic rules, corresponding to the three basic normal forms, as well as more advance rules which if followed place data in what is known as fourth,fifth and higher normal forms. The effect of normalization is to organized data around identifiers and characteristics, in successively finer and more restrictive groupings. If followed to its ultimate end normalization could result in data groupings of one or two data elements each. Data processing systems and data modelers should use these rules judiciously and should strive to achieve a balance between data models which ensure a high degree of integrity and data models which are practical from an implementation sense.
There are several other factors which should influence the grouping of data within a file. These include user access, data ownership, data maintenance requirements, data acquisition constraints, and the performance requirements and constraints of the DBMS under which the data file is implemented.
Kent discusses normalization within the framework of normal forms, that is, levels of grouping. He states that "the aim of normal forms is to ensure that if a record represents more than one fact, they are all single valued facts about the same subject, and nothing else."
A single valued fact is, as its name implies, a data element that has one and only one value. For instance, an employee's records may provide for educational courses taken. Since the employee may take several courses, the course taken element can have multiple values. This may be represented by a repeating field (course-1, course-2, etc.) or it may be represented by multiple records each of which indicates the employee identifier and the course name. Since multi-valued facts are common in the real world, and since most DBMS products allow for multivalued facts this is not normally a problem. However, the need to identify these elements and to store them properly is necessary, and since each DBMS treats these multivalued facts differently, and since some place severe restrictions on their use, the model must allow for all treatments.
Many of these constraints on data, such as when a data element may or may not have multiple values may be designed into the DBMS or they may be handled procedurally.
The end result of the normalization process, as with the classification process is to ensure that each data element is uniquely identifiable, that all data elements used to describe a given entity are grouped together and that data about multiple entities are not intermixed within the same records.
The first normal form consists of grouping atomic form data around a single key with all repeating groups eliminated. The first normal form also specifies that all records of a given type must the same number of data elements. This condition is usually interpreted to mean that repeating groups with variable numbers of repetitions are eliminated. Since these variable repeating groups, or multi-valued facts are both common and necessary, the first normal form restructures the data to break repeating groups into multiple single element records which can themselves repeat multiple times.
The classification step which most closely corresponds to this is the development of the entity families and the grouping of entities and data by characteristic value.
Second normal form ensures that no single-valued facts are dependent on only part of a key (identifier). Many designers develop records with composite keys. That is keys which combine the identifiers of two separate entities. These records are then used to store mixed data, data about each entity independently and data about the composite keyed entity. For instance a record may be constructed with the composite key of vehicle identifier and garage identifier. The data elements in that record may describe the garage name, the vehicle name and the date and cost of storing that vehicle in that garage. This poses a maintenance problem since the garage name may change and thus all records containing that name will also have to change.
The modeling techniques described in this book remove that problem since only records that represent relationships are allowed to have composite keys all other records have as their key the entity identifier and one or more characteristics.
Using classification, data groups are determined by explicit or implicit characteristics. Repeating data groups are sets of data which occur in identical form more than once. Since each data group contains an identical set of data elements, and each occurrence means something, there must be an implicit or explicit characteristics associated with each occurrences to distinguish one from another. Each occurrence is distinguished by a unique value which determines data group element contents and usage. A complete data model should show these as separate groups of data each keyed by the characteristic. Characteristic analysis and identification and characteristic value based data grouping eliminate the need for this step. Since data is grouped about a characteristic chain and grouped at each level about the characteristic values at that level, second normal form is always ensured.
Third normal form removes data dependent upon the other data within the data group. The use of both independent and dependent characteristics to identify the key structures for every data group, and the use of attribute and data group logic, ensures that every data grouping is accurately identified, and that subsequent data element assignment of all data in a data group is fully key dependent. Although these are usually referred to as functional dependency data groups in the normalization process, they are in fact characteristic dependent data groups, a condition much more clearly represented and understood from the classification viewpoint.
The ER model development segregates data about each entity into sets of records which describe only that entity. when data is necessary about two entities as a pair, a relationship is established. Thus in the example above the composite key of vehicle and garage would be replaced by a relationship "vehicle is stored in garage" and any data pertaining to the storage of that car in that garage is maintained in the relationship record which my definition must have multiple keys. Fourth normal form removes multiple multivalued dependent data from a given record. Most multivalued data elements are also characteristics.
Classification is completely value dependent, and each classification data group is dependent not only on a chain of characteristics (data elements) but on a chain of characteristic values.
A data model developed using classification techniques will not require a subsequent normalization step since all data is completely and logically classified and organized. This complete and logical classification and organization of data is the goal of both normalization and classification.
ER Models, classification and Normalization
Many of the problems of data grouping which normalization attempts to rectify are eliminated by data models which are based upon the ER model and on classification analysis. The data models descried above use classification of data within the entity, and intensional characteristics
Many of the same techniques and much of the same logic is used to analyze the relationships between between entity families (and entity groups within a family). The relationships of interest to the firm and the expression of those relationships is dependent upon the business rules of the firm and the entity family characteristics.
Although classification removes much of the need for normalization, a normalization pass should be made on the final design to detect and correct any errors within the characteristic value dependent data groups. Any errors detected should only be violations of fourth and fifth normal form, although some third normal form violations may slip through undetected by the classification analysis.
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.