Classification Overview
Categorization is a Fundamental Process
Categorizing or classifying things is a fundamental process of human existence. The world we live in, business or personal, real or conceptual is composed of myriads of things. Some of these things have very real differences between them, others are somewhat similar and still others are highly similar to each other. The differences or similarities between many of these things are sometimes more artificial than real. Distinctions are made between groups of things because it is clearer to do so than it is to refer ungrouped things. One reason for making distinctions between things is to put them into groups which are easily manageable or understandable.
In almost every case some common characteristic of these things is used to make those distinctions. Sometimes, several characteristics are required in order to make those distinctions. Because things in the real world have many characteristics, any set of characteristics they have in common can be used to make these distinctions, or to group the things. For purposes of illustration only, let us take one of the largest group of things which we deal with, people.
Obviously the world is full of people and it would be impossible to deal with or discuss people in general in any meaningful manner. There are just too many different kinds of people. There are only a few things that you can say about people in general without excluding some of them.
Once you start adding obvious physical characteristics such as age, sex, race, height, weight, color of hair, color of eyes, etc. you start to place people into groups which are smaller than the whole (people). The more characteristics you use the smaller the number of members in each group, and the more different combinations of characteristics you can use to make up each group. Once you start using characteristics (or values of characteristics) to group things you are categorizing or classifying them.
However, using additional characteristics to take a large group and divide it into smaller groups is only part of how classification works. Characteristics can be also be used to help define vague or complex ideas. For instance, ideas such as quality, utility, have long eluded definition. In many companies the concept of a customer, or in some cases a product is equally elusive.
A definition
To classify is to organize or arrange according to class or category.
A class is a set, group, collection or configuration containing members having or believed to have at least one attribute or characteristic in common.
A major process of data modeling is to determine how data required by the firm to describe each entity of interest to the firm must be grouped for optimal efficiency, accessibility and usefulness.
Classification techniques are an invaluable method for assisting the data modeler in constructing those groupings. Classification techniques can also assist the data modeler in determining the dependency relationships between those data groups, and conversely in determining which data groups are independent of each other. Classification is also the preferred method, and the most accurate method for handling that most difficult of data model chores, the modeling of roles.
Classification of Entities
An entity is a fact of being. Everything that exists in reality, or in the perception is an entity. Because entities are devoid of attributes it is not possible to classify or group them. However we can state that since everything is an entity, and everything consists of persons, places, things, concepts or events, then those things are entities by definition.
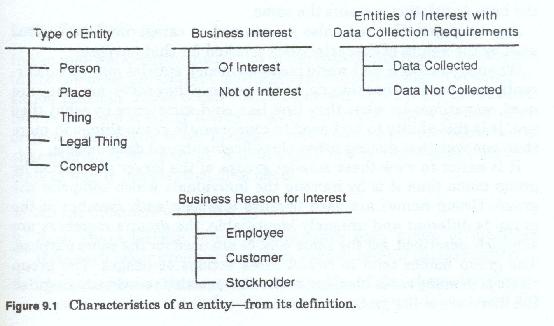
Although the definition of an entity for data modeling purposes distinguishes them into five groups, even these groups are too general to work with.
For the purposes of developing a business system design, and in particular the data models that are an integral part of those designs, each of these five classes must be divided into two, more restrictive, classes, one class containing those people, places, things concepts and events our firm is interested in and one containing those in which it is not interested.
Normally, data models do not include entities the firm is not interested in and thus they are discarded after identification.
The remaining members (figure 9-1) of each of the five now restricted classes can be further classified into two still further restrictive classes, those the firm must collect data about and those it does not have to collect data about. In this case however many models do not discard those entities about which the firm does not collect data. In those cases they are used for consistency purposes and to provide context for the remainder of the model.
We can see from this discussion that the term entity (the highest grouping in the data model) already represents three levels of categorization or grouping before we begin.
Returning to the people illustration, we now have a group called people, more specifically people the firm is interested in (for whatever reason) and more specifically people the firm is interested in and about which the firm must collect data or maintain records (for whatever reason).
This is still a fairly large group, because we are interested in different groups of people for different reasons (figure 9-2), and each of those different reasons usually dictate that we need to collect specific kinds of data about each group. However since they are all part of a larger group called people they must obviously have certain characteristics in common.
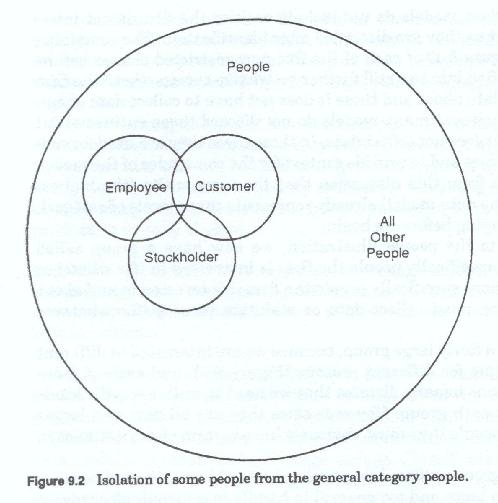
Just as we group entities into people, places, things, etc., and because entity was too large and too general to handle in a meaningful way, so too we categorize each of those groups into smaller groups, i.e. kinds of people, for ease of handling. These grouping categories may be based upon what the entities are, what they look like, what they do, what purpose they serve, how they are used, etc.,
Once the classification scheme is known, at various times during the design process, the designer can use each of these categorizations or classifications for purposes of discussion, analysis or usage, recognizing that however they decide to group them for a particular purpose, the base population remains the same.
A given population may also be grouped or categorized for various uses by the values of characteristics selected for that purpose.
When producing a real world business model, entities may be concurrently grouped by what they do, by the purpose they serve, how they are used, sometimes by what they look like, and sometimes by what they are. It is this ability to and need to concurrently group things in more than one way that distinguishes classification based data models.
It is easier to view these smaller groups of the larger population by group name than it is by naming the individuals which comprise the group. Group names are used because although each member of the group is different and uniquely identifiable, the group's members are similarly described, act the same way, or are used for the same purpose. The group names tend to reflect these actions or usages. The group name is in many cases identical to the characteristic used to distinguish the members of the group.
The more general the statement of purpose, the description of the actions or usage, or the characteristic, the more members the group will contain.
Conversely, as these statements of purpose, description of action or usage become more and more restrictive, the narrower the group becomes and the smaller the number of potential members.
Similarly, in the data model, as the definition of the characteristics becomes more and more general the group which can be included under that definition becomes larger. The more specific the characteristic definition or the more extensive the list of characteristics, the smaller the group that can be constructed.
Types, Subtypes and Groups
In many data modeling texts the terms type and subtype are used. A type is a group. There are broadly defined groups and narrowly defined groups. If a type is a broad group, than a subtype is a narrow group within the broad group. However both broad and narrow groups, groups and subgroups, types and subtypes are all still groups
Each group, broad or narrow, large or small, has some number of entities which have a set of characteristics in common. The characteristics may be very general or inclusive, or very specific or exclusive, or some combination of both.
Each entity of any given group may have many characteristics but only share some in common with other members of the group. The number of potential groups which can be formed is determined by the number of identifiable characteristics, the number of characteristics selected, and the number of meaningful combinations of characteristics for each number selected.
Entity Families
In the real world entity model and in the data entity model, we attempt to use the most general, yet most meaningful, classification or categorization possible. These broad classifications of entities are called families. A real world entity family (figure 9-3) represents a general class or group consisting of all members who share some minimum set of characteristics in common. A data entity family represents a general class of highly interrelated data about:
|
Figure 9-3 Entity family is ...
In developing entity models, we seek to identify the broad real world entity groups (or families) that populate the internal and external environment of the business (figure 9-4). Some of the entities will concern us and some will not. They all have one thing in common, they were derived ultimately from the statements of mission, goals, objectives, etc., which were used to define the strategic and tactical direction of the company and its business processing rules and determinants.
|
Figure 9-4 Entity Families
Real world entity reference and usage is within the context of the business and its concomitant actions. For representational reasons ease and clarity of definition, and ease of handling and discussion, they are segregated into subsets or groups, but all are nothing more than some aspect of the whole, and therefore unified entity.
Active versus Passive Entities
There are two additional ways in which to classify data entities, as either active or passive. Active data entities are the data entities which change over time, which do things or cause things to be done.
The other category of data entities are of interest, more so because they describe and/or relate entities. These are passive data entities. These data entities are usually fixed in data content, come about full blown, or exist more conceptually than in reality. Some examples of these are job requisitions, job or other related skills, education, locations, organizational units, sales territories, sales offices, and job descriptions, to name a few. These passive entities have static data content, and no meaningful life cycle of their own.
These data entities are describable, but in narrative terms, or as lists of other items, rather than physical things. They are carriers of a concept or an idea. Again, there is overlap between active and passive entities, mostly dependent upon viewpoint. There are no hard and fast rules, but it is important to recognize their existence. It is important in the data modeling portion of systems design to identify both active data (non-static) entities and passive (static) ones. From a business systems design standpoint they behave differently and are used differently.
Process Control Entities
There is one final class or family of data entity which appears in many data models. The family has no name, and thus can be called by any name. We will call it the process control family. Its members are used to remember sequences of data events and to guide processes, and later data events, within the organization.
If we scan all of the documentation collected and generated from the analysis phase, we would probably have a myriad of entity groups, and probably only a few entity families and no definitive way to tell which is which. Entity class, entity set and entity family are interchangeable terms within this context.
An entity family consists of all individual and groups of member entities which behave the same way in our organization. All entities which have the same role in the organization or which relate to the environment in the same way usually belong to the same family. Thus the entity family customer - contains all entities who fill the role of customers, that is who order, receive, and or pay for the products or services of the company. This family may also include both past customers, present customers, and potential customers, and these may be both active and passive.
Entity Definition
For each entity (family or otherwise) identified by the design team, a definition must also be created. These definitions will provide valuable insight into where the entity belongs, and what level of generalization it represents. For an entity family, the definition should be broad or general enough to include all members of the family. We must describe the role that the members of this family play. We must define as completely as possible, who and what are the members of this family, or more succinctly, what is the universe of this family. The definition should also permit the determination of who are and are not members of the family. This is usually stated in the form of tests or characteristics. The definitions of groups within a family will always be more restrictive than the family.
Entity Family versus Entity Group Reference
All entity references throughout the system design will either be to a family as a whole, some group of members (figure 9-5) within some family or to some individual member. All relationships are expressed in terms of an entity relating to another entity. In the business system design models, we assume that because entities relate to the environment, either explicitly or implicitly, they relate to each other as well. These relationships may be strong or weak, active or passive, and in some cases may be of no interest to the company.
|
Figure 9-5 Entity Groups
Relationships can be viewed in two ways, entity family to entity family (inter-family), and entity to entity or entity group to entity group (intra-family). These relationships, both inter- and intra-family are another manner in which the classification scheme may be represented. To illustrate:
A person may be on the faculty of, be a student of, may be an alumnus of, a trustee of, and a contributor to an educational institution. Each relationship represents a separate, distinct, noteworthy, and more importantly definable characteristic.
Likewise, a person may be a depositor of, a lender to and a borrower from, a mortgagee of, etc., a bank.
Each of these ideas may be represented by either a characteristic used to form an entity group, or by a relationship. These relationships may be direct or thorough some intermediary entity, such as an account entity.
|
Figure 9-6 Entity Groups ...
Thus each group (figure 9-6) is defined in terms of its relationship to some member of another family, rather than through shared characteristics. In this representation however the characteristic is transferred to the relationship. The model's descriptions must explain as fully as possible
Since the majority of activity within an organization can be expressed in terms of the relationships between entity and entity, or between entity and company (also an entity, by the way), we can expect that there will be a large number of intra-family relationships in the structure and that relationships between entities both intra- and inter-family will be multiple, conditional, and complex.
Distinguishing between Entities (Entity Roles)
Entity groups, at the family level and below, are primarily developed from the role which the members of each group play in the organization. In some instances however, an entity can play multiple roles. For instance:
a company can be a supplier and a customer. While these roles are distinct they are not mutually exclusive.
A bank's customer can be a borrower for a car, a depositor, and a mortgagee. Again, non-mutually exclusive.
The following are general recommendation's for entity class, or entity family identification, recommendations which also govern whether similar entities can, or should be merged into a single family, are as follows:
To illustrate:
A third alternative is also possible. This states that there are entities who play one role exclusively, but there are some which can play both. This can be handled in the following manner.
Each different role entity is defined into a different family. For each entity that is a member of both families:
Entities are assigned to a class, or family, according to the role they play in the company environment. Care must be exercised to restrict the definition of those roles. All entities in the family or class play the same role within the organization. The entities within each family or class are different, in specific, just as people are different in specifics, but alike in their general nature and description.
As with the real world, each entity is unique in that it has its own distinct set of physical attributes (descriptors) operational attributes and relationships. Thus the assumption cannot be made that all data elements within a given attribute of the entity family will be present or active for any given member group of the entity family. Overall however, those elements are needed to describe the entities in the family. Since the description of the family can only be in terms of its family members, the design team must assume that any given entity family member, may have any and thus all possible attributes and relationships.
Just as entities are treated as families, so to the entity attributes are developed for the family. For instance, the demographic data for a doctor and a teacher are different (figure 9-7). These in turn are different from the demographics of a school which in turn is different from those of a hospital. However, all of the above have some demographic data which we want to record.

The classification of attributes into descriptive, operational or relational is vague at best. The categorization of any given attribute might easily change depending upon usage. Generally speaking data that is more stable and infrequently changed is descriptive, data that is more volatile is operational, and data which is connective describes relationships. The categorization does not affect the usage or structure per se, but assists in the process of identification, segmentation, partitioning and combination. We try to combine entities with like data characteristics. Each characteristic of data should be such that it is the only place we have to reference to obtain data on that aspect of the entity. If all data characteristics are such that they could participate in the entity equation, then they are properly placed. If the characteristic of data can appear in the function equation of more than one entity, then it should be isolated.
Exception Attributes
There is a special category of data characteristics which constitute an exception to this general rule. Generally speaking, they can be termed transient exception data.
To illustrate:
The definitions of each characteristic describe their function, or role - descriptive or operational. The definitions answer the questions: What role does the characteristic play in describing the entity, its actions or our actions against it? What data would we expect to find in this characteristic, if we assume that this, and only this, characteristic described that aspect of the entity. What is the definition of this aspect of the entity? Why is that particular data characteristic needed?
Data Acquisition and Retention
Acquisition and retention of the data must also be addressed. If a characteristic is needed for a given entity, where and how is that characteristic acquired?
The narratives, for operational characteristics must address the questions, as to what is the minimum level of data necessary to support the function? How does the function relate to the entity?
If data characteristics relate to multiple functions, or multiple data events, what are the identifiers necessary to distinguish a characteristic from its siblings? If this is a repeating characteristic of data, what identifiers do we need, real or internal to distinguish its twins, its multiple parts? How many multiples may there be?
The design team should at this point be capable of creating a structure or schematic which gives pictorial representation to the entity families, groups of entities within each family, and the various facets of classifications of those groups within each family.
They have separated out all of the common data and created separate characteristics which reflect data which can be used commonly to describe both the family in general, and each group within the family. For these families they should have defined relationships or structures such that they can relate both the family members to each other, and members of different families to each other
Some of these new characteristics may themselves be described in terms of other descriptive characteristics, which are common to still larger groups. It is a general characteristic of many of these these families of entities that their description is more narrative than elemental. That is, they are conceptual in nature and can only be described by narrative.
Describing Process Control Entities
The final family of entity is one which we termed the process control entity family. Within this family are members that are kinds of events, or time sequenced things.
Within any functioning system, with randomly occurring events, there is a need to "remember" the order in which things happened, or to store the results of actions such that later actions can be taken against them. There is a need to record the results of decisions, or actions which determine which process is to be taken. There is a need to remember the results of tests which once made, govern future actions and which would be tedious to make again. In some cases randomly occurring events must be processed at some later data in a certain order. Our process control entity serves this function of "remembering" time or ordering time. In essence this entity remembers sequences of occurrences by recording lists of trigger identifiers, or entity identifiers.
To illustrate:
To further illustrate:
This conceptual family of members can be used for system and operational status checks, work allocation, process control and procedural control.
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.