What is Data Analysis?
Introduction
Business processes and data are tightly interlocked. Processes, or more specifically the sequences of tasks that business personnel engage in, collect, use and generate data. Data is both the raw material which feed business processes and the product of those processes. Most business activities either collect, maintain (update), file or disseminate data directly, or indirectly. That is, the data is a direct result of, or describes the actions of the person performing the process, or it is indirect in that it is about some action someone else has performed. It may be data about some object that the person is working with directly, or an object someone else is working with.
Data however, is not tangible. It is not something that can be picked up and handled. Data only becomes tangible when it is recorded on some media, which itself can be picked up and handled. Data thus is most often synonymous with the media used to record it. In most case, the form data takes is highly dependent on the media on which it is recorded. In addition, and perhaps more importantly, the form data takes is highly dependent upon the perceptions of person recording it, and its use is highly dependent upon the perceptions of the persons using it.
But what is data? Data is the name given to those words and numbers we use to describe the things we work with, the types of actions we take and the results of those actions.
Strictly speaking, data are facts. Within the context of business activities and data processing (in its broadest sense) data are the words, phrases and numbers we use to create those descriptions and record those results. To the extent that those words and numbers are meaningful, and accurate, they constitute information.
There are some writers that make a distinction between data and information, and to some extent that distinction is valid.
Data and Information
Most dictionaries define data in terms of information, but they do not necessarily define information in terms of data. Information is defined in terms of the communication of knowledge.
Information is the representation or recording of knowledge derived from study, experience or instruction. Data are information organized for analysis, reference, or used as the basis for a decision. Data are facts suitable for processing. Information is data that has been organized and recorded in such a manner as to become meaningful. Information is organized, recorded knowledge of a specific thing, event or situation. Information is that which communicates knowledge.
Knowledge is defined as specific information about something. From these definitions we can derive the relationships between data, information and knowledge as follows: Information is data (or facts) about a specific subject or event, organized to convey or communicate knowledge. That is, information is data that is organized to tell us something.
Data that does not tell us something is not information. Data is not always organized, or more importantly, may not be defined. The number 23666 is data, which means nothing, per se, until we attach to it the explanation (or definition) that it is the zip code for Hampton, Virginia. Data only becomes meaningful when some definition or explanation is assigned to it. We might also go so far as to say that words and or numbers without definition is not even data.
Note that the word data is used in the plural (datum is the singular form although this is hardly ever used.) This use of the plural form also tells us that a single fact (a single word or number) is usually not enough to convey information, we need multiple facts, multiple words or multiple numbers (data) or words, numbers and definitions to convey information.
For instance, a single word or number (as in the zip code above), or even a list of words or numbers in an of itself is usually meaningless without some explanation as to what those words or numbers represent.
In the case of the above five-digit number we must also give it a precise name, in this case it is a five digit zip code, to distinguish it from the nine digit (five plus four) zip code.
In the case of lists, we require some explanation as to why the specific entries in the list were assembled, and what significance if any can be attached to the order if the entries in the list. At minimum, a single word or number, requires some definition or explanation before it becomes meaningful.
From the above discussion we can arrive at the following definitions:
A brief history of data
From the earliest times, people have attempted to describe the things around them, and to create records of their actions. These records were intended to preserve for later use, information about what happened, what was happening and what was expected to happen in the future. These records cover every aspect of human interaction, both private and public, personal and interpersonal.
Some of the earliest forms of records appear as notches on sticks and bones, and to some extent as the various forms of art - cave paintings and statues.
The word history itself means a narrative of events, or a chronological record of events. To record is to set down for preservation, in writing or in other permanent form. A record is thus an account of information or facts, set down in writing or pictorially as a means of preserving knowledge. If data are clearly defined words and or numbers, if information is organized data, if information is knowledge, and if records are a way of preserving knowledge, then we can see that there is a direct link between data and the recording of knowledge.
Records were, and still are created for many different reasons. Aside from recording observations and the results of human activity, people have also attempted to record their ideas for posterity; ideas about life, beauty, nature; ideas about how and why things work the way they do. These records are the stuff and essence of the physical sciences, art, philosophy, the social sciences, etc.
The difficulties in describing things
Some of the things people have sought to record were relatively easy to set down, others much more difficult. It is easy to record the steps one goes through to perform some physical activity. It is somewhat more difficult to describe something physical, such as a house, a tree, an animal. These things can be seen and felt, and although most people see these things the same way, there are slight differences in perspective, orientation, and experience which make those perceptions different, and these differences make the descriptions different.
There are also differences in people's ability to make those recordings. These differences show up in vocabulary, use of words, sentence and phrase construction, style, technique, and a myriad other things which differentiate the ordinary from the brilliant. In addition, some people are more observant than others, and some are more meticulous in their description. Some, as noted above, just have a wider vocabulary or make better choices of words and can thus describe things is more picturesque manner, more meaningfully, more clearly, or in more detail.
If problems, and differences of perception and thus of description arise when people describe the physical, is it any wonder that even more problems arise when they venture into the realm of the ideas, the things which cannot be seen or felt.
It is in the realms of art, writing (fiction and nonfiction), theoretical science and philosophy that the portrayal of ideas is attempted most frequently. The artist must first select his subjects, and then the perspectives he or she wishes to portray. The artist must then chose the media - oils, pastels, charcoal, etc., - and then the colors to be used. The artist must determine what to highlight and what to make subdued, where to place emphasis and where to draw focus.
The writer, scientist and philosopher must develop an understanding of his ideas, solidify those ideas into words and present those ideas logically. The choice of words, perspectives and emphasis is as important here as in the realm of art, perhaps even more so. The writer, unlike the artist must rely on mental imagery to convey his ideas.
When we look at a painting or a sculpture we see what the artist saw, or more specifically what the artist wanted us to see. When we read words, we do not necessarily understand what the writer wanted to convey. We do not know how closely, nor how completely, our understanding of the ideas matches that of the writer. Because ideas are intangible, and usually not based upon something real (tangible) they are difficult to describe, even when pictures and diagrams are employed.
Describing a system
Business systems are concepts or ideas. One cannot pick up a business system, in most cases one cannot see a business system, although one can see many of its components - activities and recorded data.
Systems analysts and systems designers, although they use both words and pictures (diagrams or models) to describe the results of their analysis, and the requirements and specifications of the business systems they create, are in many ways more like the writers than the artists. They use words and diagrams to describe ideas, intangibles, things which exist and things which do not exist. Unlike the artist, and in some cases the writer who describe things that are fixed, or static, systems analysts and systems designers attempt to describe things which are dynamic. That is they try to describe things which are constantly changing or constantly moving. They describe actions being performed, and actions as they should be performed. They describe work flows, document flows and the documents and reports that carry business data. However, they must also describe the environment that they are creating these business systems for and in which these business systems exist. They describe the environment that these business systems create. All of these descriptions are conceptual, they are ideas and perceptions of a reality. More importantly they must describe the data that fuels the business, the data that is carried on the documents and reports. This description of data is not of the words and numbers, but of the meaning of the words and numbers. In many cases they must also determine, or select the words and numbers to be used to create these descriptions and then determine the definitions to be used to apply meaning to them.
The analyst must look at data and the meanings assigned to data from several perspectives. The first perspective is that of the business community being supported by the system and who therefore use the data. For these people the analyst must determine the requirements for data, for information, and most importantly for knowledge. The second perspective is that of the programmers and the computers they work with. For these people, the analyst must determine coding structures, automated record contents, and other automation related requirements.
It is the analysis of data requirements and description of those data requirements, that is the concern of this book, for as we have seen, data are just facts - words and numbers with definitions attached.
The analyst must address several problems. First, the selection of the appropriate facts to use. Second, to determine how to organize those facts to make them most useful. And third, how to present or record those facts, and what recording media to use.
Thus we arrive at another definition;
Background of data requirements analysis
In order to understand both data analysis as it is practiced today as a part of the systems analysis and systems design processes, and to understand the problems inherent in data analysis, one must have some understanding of its history.
Modern data analysis practices are the result of many parallel and interrelated trends. The effects of these influences are not uniform in all organizations, but they are present to some degree in just about every organization today. They are:
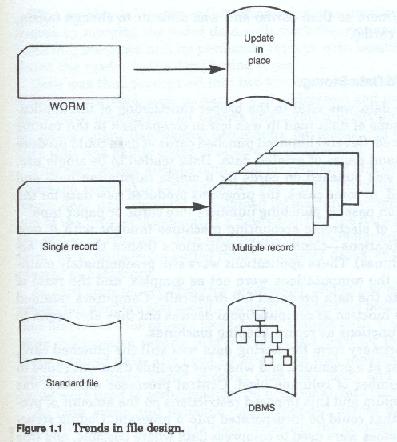
The movement from permanent data recording technology (WORM - write once, read many times) to update in place technology
The movement from single record design to fragmented or segmented record design and the growth in the number of record types contained application files
The movement from an application or process orientation of file design to a central file or entity orientation of file design - from single user function/single user organization application files to multi-user function/multi-user organization application files
The movement from standard file access methods to Data Base Management System (DBMS) management of data and still further, from single DBMS organizations to multiple DBMS organizations
The movement from batch processing to on-line processing of data and the growth in the number of users of those on-line systems
The movement from cyclic to real-time currency of data
The movement from generalized responsibility for data related activities to specialized responsibility for data related activities in the systems life cycle - from Systems Analysis and Systems Designers to Data Base Administrators to Data Administrators to Data/Information Resource Management Organizations
The movement from predominantly manual generation of systems analysis and design documentation to CASE (Computer Assisted Software Engineering) assisted system life cycle documentation
The movement from operationally oriented data files to data files which must support all levels of the organization, and the growth in the demand for data within today's corporations
The growth in the number of files used in each application and the size of these files Each of these trends (figure 1-1) are having substantial and recognizable effects on the techniques for developing systems and on that set of system development activities know today as data analysis.
In the early days of data processing most applications of automation were scientific, and thus statistical or highly mathematical. That is, the computers were programmed to solve complex formulas or computations. These computations relied on relatively (by today's standards) small amounts of data (numbers). Data were entered into the machine for computation in one of two forms, punched cards or punched paper tape. Most punched cards held either forty or eighty columns of data (figure 1-2). Paper tape held more data but was less commonly used because it was delicate (more so than cards) and was difficult to change (again, more so than cards).
Punched Card Data Storage
Although the data was vital to the proper functioning of the applications, the volume of data read in was low in comparison to the volume of data produced. Several hundred punched cards of data could produce several thousand pages of printed data. Data tended to be single use, that is data was punched on cards for a single calculation pass, and then discarded. In some cases, the programs produced new data for the next calculation pass by punching numbers into cards or paper tape.
The advent of electronic accounting machines brought with it new kinds of applications - commercial applications (hence the name accounting machines). These applications were still predominately mathematical, but the computations were not as complex, and the ratio of data read in to the data produced fell drastically. Computers retained their primary function as computational devices but they also began to take on new functions as record keeping machines.
Since the primary form for storing data was still the punched card, data space was a premium, and wherever possible data was coded to reduce the number of columns used. Central Processor memory was also at a premium and this imposed restrictions on the amount of processing logic that could be incorporated into a program. Coding structures and schemes were used to compress data where possible, and this compresses, coded data was passed on to the output reports. Codes were used most frequently when the potential values for a data item contents could be represented by, and thus selected from a relatively short list of entries. Codes were usually developed such that a single (or in the case of a long list - two) digit number (or character) corresponded to each entry in a list.
Because each update cycle of the application (each execution of the program) produced changes to these records, requiring a new set of cards to be produced, many systems designers devoted extensive effort to developing card formats in which a single card corresponded to a single item record - a single inventory account, payroll account, or budget account.
This data compression had several effects, first it reduced the processing time, since card readers, and more specifically card punching was extremely slow (especially by today's standards), it simplified program logic in many cases to "If.. then...else" style logic: test a code field and processing according to the rules for that code. The adverse affect was that reports produced from this data was extremely cryptic, unless one had extensive reference sheets to decipher the code meanings.
This problem of highly coded information was ameliorated to some degree by merging the coded data with more descriptive data cards for reporting purposes, and by producing reports with headings which assisted the reader in the deciphering chore.
Data was thus segregated into two kinds - static data (data used for reference purposes such as names and addresses) and used to provide descriptive information on reports and forms, and dynamic data (used for totals, quantities, payroll deductions, payments and receipts, etc.), data that was highly coded or otherwise compressed.
This segregation allowed data used for reference and descriptive purposes (on reports) to be maintained apart from the dynamic data. Dynamic data was normally maintained by machine, where each cycle or run of the programs generated a new version of the data records, while the static, or reference data was maintained predominantly in manual form, with cards being pulled from the master decks, changed and replaced, as necessary.
As card processing technology progressed, and as processing units increased in memory and speed, application programs became more complex, and could thus process more data in a single pass. User demand for more informative reports also increased the need for more data, and more complex data. The need for more data was accommodated in two ways: first, more highly encoded was used, and second, more cards were used to accommodate the additional data items.
As both static and dynamic data expanded across multiple cards, each card had to have a data item to identify the account, employee, inventory item, invoice, etc., that its contents represented, and additional data items to reflect the card type and card sequence number.
Where multiple cards were used to store both dynamic and static data each card had a specific format, field layout, or kind of content. As applications, and thus data became more complex, sets of cards were used to store a single records worth of data and more and more codes had to be added to identify the kind of data on each card. That is the programs had to be able to identify what kind of card they were reading so that they could determine the kind of data that was expected on that card.
Each different format was identified by a code such that the programs could integrate the code and determine what data items were expected on that kind of card. In some cases, sets of cards were used with the same layout. Where the application required these cards to be processed in a specific sequence an additional data element was added to ensure that that sequence was maintained. This type of card set design was used most frequently on order and invoice processing systems, where multiple lines of address, and multiple item lines were needed for a single document, and each address line or each item line was represented by a single card.
Magnetic Media Data Storage
With the introduction of magnetic storage media - disk, tape and drum - systems designers were able to effect several major changes in data file design. Although drum storage was around for a substantial period of time, it was slow, had relatively limited capacity and was moderately expensive. Drum technology never really gained the popularity that tape or disk (DASD) enjoyed and today except for isolated instances drum applications are almost nonexistent.
Magnetic media, more so DASD than tape, allowed systems designers to make many significant changes to their designs.
First they were able to build longer records, having been released from the forty or eighty character limitation of cards. Second, they were able to build larger files and were able to process them faster due to the speed of the recording devices, third, they were able to develop update in place applications, at least with drum and disk. They were also released from several other limitations, one being the number of concurrent files which could be input into an application program, and second the requirement to process all files sequentially rather than randomly.
These media allowed for the introduction of randomly accessed reference files, easy resequencing of data files, more frequent updating of data files, and enabled the movement to on-line style applications.
Limiting factors on magnetic media
As systems designers designed applications using this new technology they incorporated the same data file design techniques as they used in the card environment. Data that was migrated from card to tape and disk retained its format and eighty position flavor. Many early file designs retained the same concepts and tape records appeared in multiples of eighty characters.
Although tape and disk technology were introduced at much the same time, much of the processing was tape oriented. This was due to the relative speed and capacity of the tapes versus the disks, and more importantly the cost of the media. Tapes could be removed and stored easily, and tapes were much less expensive and had a higher capacity that disks. Tapes were also exclusively sequential processing media and most systems designers had extensive experience in the techniques involved in sequential file processing.
Many of these applications were oriented around the "old master - new master" processing, with one or more transaction files and master files being input to the applications and a new, updated, master being the primary output. This method of systems design also carried forward the cyclic processing nature of earlier card systems - that is the currency of the data in the files reflected the timing of the processing cycles.
These early magnetic media files also carried forward the multiple record format of the card processing systems. The difference being that the records on magnetic media were not restricted to eighty characters. This mode was known as master-detail processing in that the data for a given subject (invoice, purchase order, employee record, etc., was contained on multiple coded records each of which was identified by the subject identifier and as with the card formats some code which identified the type of record being processed. Usually the first record contained static information and the detail records contained variable, dynamic, or multiply occurring groups of data.
The processing logic for these kinds of files was difficult and cumbersome, and prone to errors of file processing logic, due to the variable number of record occurrences - and thus the variable amount of data. In order to obtain the complete set of data for a given subject the application had to process all of the records associated with that record identifier.
Magnetic processing also introduced variable length record processing and while this resolved some of the problems with processing multiple record type files, they introduced other processing problems resulting from the effort to decode field identifiers and the determination of which fields were and were not present.
Variable record length processing was effective where variable record lengths were combined with fixed record formats. That is files were designed in such a manner that each record was fixed in length but each record type contained a different length record.
As disk storage processing technology advanced other access methods were introduced which combined the advantages of sequential processing with random processing strategies - that of associating indices with either sequential or random access files so that the data could be accessed in either mode. Indices however were initially limited to single record format files, and to fixed length records.
Data Base technology
As they gained experience with disk processing techniques supplied by the hardware and operating system vendors, many large companies, including some hardware and software vendors experimented with new disk access techniques and methods for providing even more flexible file processing. These combined indexing mechanisms with both fixed and variable length record formats and with the earlier master-detail, or multi-format record file processing concepts. These new access mechanisms or access methods added file processing logic which allowed for chaining records together via pointers (physical record location addresses) contained in one record which pointed to the next record in sequence. This allowed for more flexible formats (figure 1-3) since the individual record types comprising the complete subject record no longer had to be physically contiguous but could be scattered throughout the physical file. This processing worked provided that the pointer chains remained in tact.
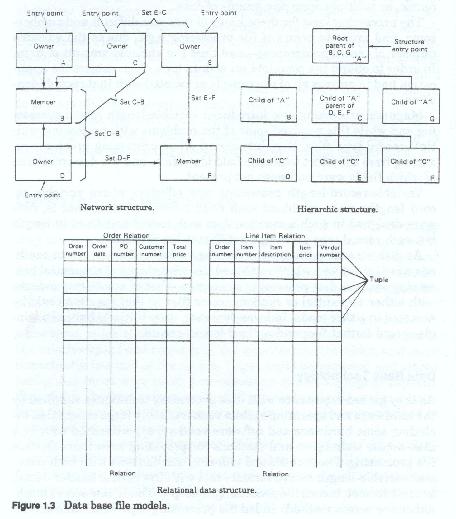
As these early experiments evolved, the complex file/record management, access, retrieval and update logic was extracted from the processing programs and replaced with common code which could be invoked from the application programs and could be directed to perform specific tasks through strings of parameters passed during the invocation processing.
These new complex file processing techniques were commercialized in the late sixties and early seventies under the general name Data Base Management System (DBMS).
The effects on Data file design
As each of these advances in technology were introduced and absorbed, they added new and more complex considerations to the problems of file design. As file design options increased, specialists emerged for each type, first tape and disk file processing and design specialists, then later data base design specialists. Although initially these people were technicians who specialized in physical design considerations, physical file implementation, data base management system parameter selection and coding, and file access performance, other advances and concepts were introduced which caused these technicians to assume other analysis and design responsibilities within the systems life cycle.
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.